Кодування даних
Вступ та позначення
Щоб використовувати квантовий алгоритм, класичні дані потрібно якимось чином завантажити у квантову схему. Зазвичай це називають кодуванням даних, але також використовують термін завантаження даних. Пригадай з попередніх уроків поняття відображення ознак — відображення ознак даних з одного простору в інший. Сам по собі перенос класичних даних на квантовий комп'ютер є своєрідним відображенням і може називатися відображенням ознак. На практиці вбудовані відображення ознак у Qiskit (наприклад, z_feature_map та zz_feature_map) зазвичай включають шари обертань та шари заплутування, що розширюють стан до великої кількості вимірів у просторі Гільберта. Цей процес кодування є критично важливою частиною алгоритмів квантового машинного навчання і безпосередньо впливає на їхні обчислювальні можливості.
Деякі з описаних нижче методів кодування можна ефективно моделювати класично; це особливо легко побачити у методах кодування, що породжують добуткові стани (тобто не заплутують кубіти). Пам'ятай, що квантова перевага найімовірніша тоді, коли квантоподібна складність набору даних добре відповідає методу кодування. Тому дуже ймовірно, що тобі доведеться написати власні схеми кодування. Тут ми демонструємо широкий спектр можливих стратегій кодування, щоб ти міг порівняти їх між собою й зрозуміти, що взагалі можливо. Є кілька дуже загальних тверджень щодо корисності методів кодування. Наприклад, efficient_su2 (див. нижче) з повною схемою заплутування набагато більш схильний захоплювати квантові особливості даних, ніж методи, що породжують добуткові стани (наприклад, z_feature_map). Але це не означає, що efficient_su2 є достатнім або достатньо підходящим для твого набору даних, щоб забезпечити квантове прискорення. Це вимагає ретельного розгляду структури даних, що моделюються або класифікуються. Також існує компроміс щодо глибини схеми: багато відображень ознак, що повністю заплутують кубіти в схемі, дають дуже глибокі схеми — надто глибокі для отримання придатних результатів на сучасних квантових комп'ютерах.
Позначення
Набір даних — це множина з векторів даних: , де кожен вектор є -вимірним, тобто . Це можна розширити на комплексні ознаки. У цьому уроці ми іноді використовуватимемо ці позначення для повного набору та його конкретних елементів, наприклад . Але переважно ми говоритимемо про завантаження одного вектора з набору даних за раз і часто просто посилатимемося на один вектор із ознак як .
Крім того, для посилання на відображення ознак вектора даних зазвичай використовують символ . У квантових обчисленнях зокрема прийнято позначати відображення через — нотація, що підкреслює унітарну природу цих операцій. Обидва символи можна правомірно використовувати для одного й того ж; обидва є відображеннями ознак. У цьому курсі ми зазвичай використовуємо:
- — коли говоримо про відображення ознак у машинному навчанні загалом, і
- — коли обговорюємо реалізації відображень ознак у вигляді схем.
Нормалізація та втрата інформації
У класичному машинному навчанні ознаки тренувальних даних часто «нормалізують» або масштабують, що нерідко покращує роботу моделі. Один із поширених способів — мін-макс нормалізація або стандартизація. При мін-макс нормалізації стовпці ознак матриці даних (скажімо, ознака ) нормалізуються:
де min і max — мінімум і максимум ознаки по векторам даних у наборі . Усі значення ознак потрапляють у одиничний інтервал: для всіх , .
Нормалізація — також фундаментальне поняття в квантовій механіці та квантових обчисленнях, але воно дещо відрізняється від мін-макс нормалізації. Нормалізація в квантовій механіці вимагає, щоб довжина (у контексті квантових обчислень — 2-норма) вектора стану дорівнювала одиниці: , що забезпечує суму ймовірностей вимірювань, рівну 1. Стан нормалізується діленням на 2-норму, тобто масштабуванням
У квантових обчисленнях і квантовій механіці це не нормалізація, яку люди нав'язують даним, а фундаментальна властивість квантових станів. Залежно від схеми кодування це обмеження може впливати на масштабування твоїх даних. Наприклад, при амплітудному кодуванні (див. нижче) вектор даних нормалізується , як того вимагає квантова механіка, і це впливає на масштаб даних, що кодуються. При фазовому кодуванні рекомендується масштабувати значення ознак так, щоб , щоб уникнути втрати інформації через ефект модуля при кодуванні у фазовий кут кубіта[1,2].
Методи кодування
У наступних кількох розділах ми посилатимемося на невеликий приклад класичного набору даних , що складається з векторів даних, кожен із ознаками:
У введених вище позначеннях можна сказати, наприклад, що ознака вектора даних нашого набору є .
Базисне кодування
Базисне кодування кодує класичний рядок із бітів у обчислювальний базисний стан -кубітної системи. Розглянемо, наприклад, Це можна представити як -бітний рядок , а в -кубітній системі — як квантовий стан . Загалом, для -бітного рядка: , відповідний -кубітний стан є , де при . Зверни увагу, що це стосується лише однієї ознаки.
Базисне кодування у квантових обчисленнях представляє кожен класичний біт як окремий кубіт, відображаючи двійкове представлення даних безпосередньо на квантові стани в обчислювальному базисі. Коли потрібно закодувати кілька ознак, кожна ознака спершу перетворюється у двійкову форму, а потім призначається окремій групі кубітів — по одній групі на ознаку — де кожен кубіт відповідає одному біту двійкового представлення цієї ознаки.
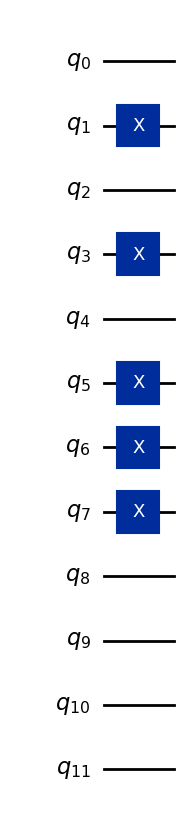
Як приклад, закодуємо вектор (5, 7, 0).
Припустимо, всі ознаки зберігаються у чотирьох бітах (більше, ніж потрібно, але достатньо для представлення будь-якого однозначного числа в десятковій системі):
5 → binary 0101
7 → binary 0111
0 → binary 0000
Ці бітові рядки призначаються трьом наборам із чотирьох кубітів кожен, тому загальний 12-кубітний базисний стан:
Тут перші чотири кубіти представляють першу ознаку, наступні чотири — другу ознаку, а останні чотири — третю ознаку. Наведений нижче код перетворює вектор даних (5,7,0) у квантовий стан і узагальнений для роботи з іншими однозначними ознаками.
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit
from qiskit import QuantumCircuit
# Data point to encode
x = 5 # binary: 0101
y = 7 # binary: 0111
z = 0 # binary: 0000
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, "04b")] # [0,1,0,1]
y_bits = [int(b) for b in format(y, "04b")] # [0,1,1,1]
z_bits = [int(b) for b in format(z, "04b")] # [0,0,0,0]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,1,0,1,1,1,0,0,0,0]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw("mpl")
Перевір своє розуміння
Прочитай питання нижче, подумай над відповіддю, а потім натисни на трикутник, щоб побачити рішення.
Напиши код для кодування першого вектора нашого прикладного набору даних :
за допомогою базисного кодування.
Відповідь:
import math
from qiskit import QuantumCircuit
# Data point to encode
x = 4 # binary: 0100
y = 8 # binary: 1000
z = 5 # binary: 0101
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, '04b')] # [0,1,0,0]
y_bits = [int(b) for b in format(y, '04b')] # [1,0,0,0]
z_bits = [int(b) for b in format(z, '04b')] # [0,1,0,1]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,0,1,0,0,0,0,1,0,1]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw('mpl')
Амплітудне кодування
Амплітудне кодування кодує дані в амплітуди квантового стану. Воно представляє нормалізований класичний -вимірний вектор даних як амплітуди -кубітного квантового стану :
де — та сама розмірність векторів даних, що й раніше, — -й елемент , а — -й обчислювальний базисний стан. Тут — константа нормалізації, яка визначається з даних, що кодуються. Це умова нормалізації, яку накладає квантова механіка:
Загалом це відрізняється від мін-макс нормалізації, що застосовується до кожної ознаки по всіх векторах даних. Те, як саме це буде вирішуватися, залежатиме від твоєї задачі. Але від умови нормалізації квантової механіки, наведеної вище, нікуди не дітися.
При амплітудному кодуванні кожна ознака вектора даних зберігається як амплітуда різного квантового стану. Оскільки система з кубітів має амплітуд, амплітудне кодування ознак вимагає кубітів.
Як приклад, закодуємо перший вектор нашого прикладного набору даних , , за допомогою амплітудного кодування. Нормалізуючи отриманий вектор, отримуємо:
і отриманий 2-кубітний квантовий стан буде:
У наведеному прикладі кількість ознак вектора не є степенем 2. Коли не є степенем 2, ми просто вибираємо кількість кубітів таку, що , і доповнюємо вектор амплітуд «нейтральними» константами (тут — нулем).
Як і при базисному кодуванні, після обчислення стану, що кодуватиме наш набір даних, у Qiskit можна скористатися функцією initialize для його підготовки:
import math
desired_state = [
1 / math.sqrt(105) * 4,
1 / math.sqrt(105) * 8,
1 / math.sqrt(105) * 5,
1 / math.sqrt(105) * 0,
]
qc = QuantumCircuit(2)
qc.initialize(desired_state, [0, 1])
qc.decompose(reps=5).draw(output="mpl")

Перевага амплітудного кодування — вже згадана вимога лише кубітів. Однак наступні алгоритми мають оперувати амплітудами квантового стану, а методи підготовки та вимірювання квантових станів зазвичай є неефективними.
Перевір своє розуміння
Прочитай питання нижче, подумай над відповідями, а потім натисни на трикутники, щоб побачити рішення.
Запиши нормалізований стан для кодування такого вектора (складеного з двох векторів нашого прикладного набору даних):
за допомогою амплітудного кодування.
Відповідь:
Щоб закодувати 6 чисел, нам потрібно мати принаймні 6 доступних станів, на амплітудах яких можна закодувати дані. Для цього знадобляться 3 кубіти. Використовуючи невідомий коефіцієнт нормалізації , запишемо:
Зверни увагу, що
Отже, нарешті,
Для того ж вектора даних напиши код для створення схеми, що завантажує ці ознаки за допомогою амплітудного кодування.
Відповідь:
desired_state = [
9 / math.sqrt(270),
8 / math.sqrt(270),
6 / math.sqrt(270),
2 / math.sqrt(270),
9 / math.sqrt(270),
2 / math.sqrt(270),
0,
0,
]
print(desired_state)
qc = QuantumCircuit(3)
qc.initialize(desired_state, [0, 1, 2])
qc.decompose(reps=8).draw(output="mpl")
[0.5477225575051662, 0.48686449556014766, 0.36514837167011077, 0.12171612389003691, 0.5477225575051662, 0.12171612389003691, 0, 0]

Може знадобитися працювати з дуже великими векторами даних. Розглянь вектор
Напиши код для автоматизації нормалізації та генерації квантової схеми для амплітудного кодування.
Відповідь:
Є багато можливих відповідей. Ось код, що виводить кілька проміжних кроків:
import numpy as np
from math import sqrt
init_list = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5]
qubits = round(np.log(len(init_list)) / np.log(2) + 0.4999999999)
need_length = 2**qubits
pad = need_length - len(init_list)
for i in range(0, pad):
init_list.append(0)
init_array = np.array(init_list) # Unnormalized data vector
length = sqrt(
sum(init_array[i] ** 2 for i in range(0, len(init_array)))
) # Vector length
norm_array = init_array / length # Normalized array
print("Normalized array:")
print(norm_array)
print()
qubit_numbers = []
for i in range(0, qubits):
qubit_numbers.append(i)
print(qubit_numbers)
qc = QuantumCircuit(qubits)
qc.initialize(norm_array, qubit_numbers)
qc.decompose(reps=7).draw(output="mpl")
Normalized array: [0.17342199 0.34684399 0.21677749 0.39019949 0.34684399 0.26013299 0.086711 0.39019949 0.086711 0.21677749 0.30348849 0. 0.1300665 0.30348849 0.21677749 0. ]
[0, 1, 2, 3]
Чи бачиш ти переваги амплітудного кодування над базисним? Якщо так, поясни.
Відповідь:
Може бути кілька відповідей. Одна з них: оскільки базисні стани впорядковані фіксовано, це амплітудне кодування зберігає порядок закодованих чисел. Крім того, воно, як правило, є більш щільним.
Перевага амплітудного кодування полягає в тому, що для -вимірного (-ознакового) вектора даних потрібно лише кубітів. Однак амплітудне кодування загалом є неефективною процедурою, що вимагає довільної підготовки стану, яка є експоненційною за кількістю вентилів CNOT. Іншими словами, підготовка стану має поліноміальну часову складність за кількістю вимірів, де , а — кількість кубітів. Амплітудне кодування «забезпечує експоненційну економію простору ціною експоненційного збільшення часу»[3]; однак у певних випадках можна досягти часової складності [4]. Для наскрізного квантового прискорення необхідно враховувати часову складність завантаження даних.
Кутове кодування
Кутове кодування становить інтерес у багатьох моделях QML, що використовують відображення ознак Паулі, наприклад квантові машини опорних векторів (QSVM) та варіаційні квантові схеми (VQC), серед інших. Кутове кодування тісно пов'язане з фазовим кодуванням і щільним кутовим кодуванням, які розглядаються нижче. Тут ми використовуватимемо «кутове кодування» для позначення обертання в , тобто обертання від осі , що виконується, наприклад, за допомогою вентиля або [1,3]. Насправді можна кодувати дані в будь-якому обертанні або їх комбінації. Але є загальноприйнятим у літературі, тому ми наголошуємо саме на ньому.
При застосуванні до одного кубіта кутове кодування надає обертання навколо осі Y, пропорційне значенню даних. Розглянемо кодування однієї () ознаки з вектора даних у наборі, :
Альтернативно, кутове кодування можна виконувати за допомогою вентилів , однак закодований стан матиме комплексну відносну фазу порівняно з .
Кутове кодування відрізняється від двох попередніх розглянутих методів у кількох аспектах. При кутовому кодуванні:
- Кожне значення ознаки відображається на відповідний кубіт, , залишаючи кубіти у добутковому стані.
- Кодується одне числове значення за раз, а не цілий набір ознак точки даних.
- Для ознак даних потрібно кубітів, де . Тут часто виконується рівність. Ми побачимо, як можливе , у наступних кількох розділах.
- Отримана схема має константну глибину (як правило, глибина дорівнює 1 до транспіляції).
Квантова схема константної глибини робить цей метод особливо придатним для сучасного квантового обладнання. Додаткова перевага кодування даних за допомогою (і зокрема, нашого вибору кутового кодування по осі Y) полягає в тому, що воно створює квантові стани з дійсними значеннями, що може бути корисним для певних застосувань. При обертанні навколо осі Y дані відображаються вентилем обертання на дійсний кут (Qiskit RYGate). Як і при фазовому кодуванні (див. нижче), рекомендується масштабувати дані так, щоб , щоб запобігти втраті інформації та іншим небажаним ефектам.
Наступний код Qiskit обертає один кубіт із початкового стану , щоб закодувати значення даних .
from qiskit.quantum_info import Statevector
from math import pi
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
Визначимо функцію для візуалізації дії на вектор стану. Деталі визначення функції не важливі, але здатність візуалізувати вектори стану та їх зміни є важливою.
import numpy as np
from qiskit.visualization.bloch import Bloch
from qiskit.visualization.state_visualization import _bloch_multivector_data
def plot_Nstates(states, axis, plot_trace_points=True):
"""This function plots N states to 1 Bloch sphere"""
bloch_vecs = [_bloch_multivector_data(s)[0] for s in states]
if axis is None:
bloch_plot = Bloch()
else:
bloch_plot = Bloch(axes=axis)
bloch_plot.add_vectors(bloch_vecs)
if len(states) > 1:
def rgba_map(x, num):
g = (0.95 - 0.05) / (num - 1)
i = 0.95 - g * num
y = g * x + i
return (0.0, y, 0.0, 0.7)
num = len(states)
bloch_plot.vector_color = [rgba_map(x, num) for x in range(1, num + 1)]
bloch_plot.vector_width = 3
bloch_plot.vector_style = "simple"
if plot_trace_points:
def trace_points(bloch_vec1, bloch_vec2):
# bloch_vec = (x,y,z)
n_points = 15
thetas = np.arccos([bloch_vec1[2], bloch_vec2[2]])
phis = np.arctan2(
[bloch_vec1[1], bloch_vec2[1]], [bloch_vec1[0], bloch_vec2[0]]
)
if phis[1] < 0:
phis[1] = phis[1] + 2 * pi
angles0 = np.linspace(phis[0], phis[1], n_points)
angles1 = np.linspace(thetas[0], thetas[1], n_points)
xp = np.cos(angles0) * np.sin(angles1)
yp = np.sin(angles0) * np.sin(angles1)
zp = np.cos(angles1)
pnts = [xp, yp, zp]
bloch_plot.add_points(pnts)
bloch_plot.point_color = "k"
bloch_plot.point_size = [4] * len(bloch_plot.points)
bloch_plot.point_marker = ["o"]
for i in range(len(bloch_vecs) - 1):
trace_points(bloch_vecs[i], bloch_vecs[i + 1])
bloch_plot.sphere_alpha = 0.05
bloch_plot.frame_alpha = 0.15
bloch_plot.figsize = [4, 4]
bloch_plot.render()
plot_Nstates(states, axis=None, plot_trace_points=True)

Це була лише одна ознака одного вектора даних. При кодуванні ознак у кути обертання кубітів, скажімо для вектора даних закодований добутковий стан матиме такий вигляд:
Зазначимо, що це еквівалентно
Перевір себе
Прочитай запитання нижче, подумай над відповідями, а потім натисни трикутники, щоб побачити рішення.
Закодуй вектор даних за допомогою кутового кодування, як описано вище.
Відповідь:
qc = QuantumCircuit(3)
qc.ry(0, 0)
qc.ry(2 * math.pi / 4, 1)
qc.ry(2 * math.pi / 2, 2)
qc.draw(output="mpl")

Якщо використовувати кутове кодування, як описано вище, скільки кубітів потрібно для кодування 5 ознак?
Відповідь: 5
Фазове кодування
Фазове кодування дуже схоже на кутове кодування, описане вище. Фазовий кут кубіта — це речовий кут навколо осі від осі +. Дані відображаються за допомогою фазового повороту , де (детальніше дивись у Qiskit PhaseGate). Рекомендується масштабувати дані так, щоб . Це запобігає втраті інформації та іншим потенційно небажаним ефектам[1,2].
Кубіт зазвичай ініціалізується у стані , який є власним станом оператора фазового повороту — тобто стан кубіта спочатку потрібно повернути, перш ніж реалізувати фазове кодування. Тому логічно ініціалізувати стан воротами Адамара: . Фазове кодування на одному кубіті означає надання відносної фази, пропорційної значенню даних:
Процедура фазового кодування відображає кожне значення ознаки на фазу відповідного кубіта, . Загалом фазове кодування має глибину схеми 2, включаючи шар Адамара, що робить його ефективною схемою кодування. Фазово-закодований багатокубітний стан ( кубітів для ознак) є добутковим станом:
Наведений нижче код Qiskit спочатку готує початковий стан одного кубіта, обертаючи його воротами Адамара, а потім знову обертає його фазовими воротами, щоб закодувати ознаку даних .
qc = QuantumCircuit(1)
qc.h(0) # Hadamard gate rotates state down to Bloch equator
state1 = Statevector.from_instruction(qc)
qc.p(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
qc.draw("mpl", scale=1)

Обертання у можна візуалізувати за допомогою функції plot_Nstates, яку ми визначили раніше.
plot_Nstates(states, axis=None, plot_trace_points=True)

На графіку сфери Блоха показано поворот навколо осі Z: , де . Світло-зелена стрілка показує кінцевий стан.
Фазове кодування використовується в багатьох квантових картах ознак, зокрема у і картах ознак, а також у загальних картах ознак Паулі та інших.
Перевір себе
Прочитай запитання нижче, подумай над відповідями, а потім натисни трикутники, щоб побачити рішення.
Скільки кубітів потрібно для зберігання 8 ознак за допомогою фазового кодування, як описано вище?
Відповідь: 8
Напиши код для вектора з використанням фазового кодування.
Відповідь:
Варіантів може бути багато. Ось один приклад:
phase_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0]
qc = QuantumCircuit(len(phase_data))
for i in range(0, len(phase_data)):
qc.h(i)
qc.rz(phase_data[i] * 2 * math.pi / float(max(phase_data)), i)
qc.draw(output="mpl")

Щільне кутове кодування
Щільне кутове кодування (ЩКК, Dense Angle Encoding — DAE) — це комбінація кутового та фазового кодування. ЩКК дозволяє закодувати два значення ознак в одному кубіті: один кут — обертанням навколо осі Y, а другий — обертанням навколо осі : . Воно кодує дві ознаки таким чином:
Кодування двох ознак даних на один кубіт дає зменшення необхідної кількості кубітів у рази. Узагальнюючи це на більшу кількість ознак, вектор даних можна закодувати як:
ЩКК можна узагальнити до довільних функцій двох ознак замість синусоїдальних функцій, використаних тут. Це називається загальним кубітним кодуванням (general qubit encoding)[7].
Як приклад ЩКК, наведений нижче код кодує та візуалізує кодування ознак і .
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(3 * pi / 8, 0)
state2 = Statevector.from_instruction(qc)
qc.rz(7 * pi / 4, 0)
state3 = Statevector.from_instruction(qc)
states = state1, state2, state3
plot_Nstates(states, axis=None, plot_trace_points=True)

Перевір себе
Прочитай запитання нижче, подумай над відповідями, а потім натисни трикутники, щоб побачити рішення.
Виходячи з викладеного вище, скільки кубітів потрібно для кодування 6 ознак за допомогою щільного кодування?
Відповідь: 3
Напиши код для завантаження вектора з використанням щільного кутового кодування.
Відповідь:
Зверни увагу, що список доповнено нулем «0», щоб уникнути проблеми з одним невикористаним параметром у схемі кодування.
dense_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5, 0]
qc = QuantumCircuit(int(len(dense_data) / 2))
entry = 0
for i in range(0, int(len(dense_data) / 2)):
qc.ry(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.rz(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.draw(output="mpl")

Кодування за допомогою вбудованих карт ознак
Кодування у довільних точках
Кутове кодування, фазове кодування та щільне кодування формують добуткові стани, де кожна ознака кодується на окремому кубіті (або дві ознаки на кубіт). Це відрізняє їх від базисного та амплітудного кодування, які використовують заплутані стани. Тут немає відповідності 1:1 між ознакою даних і кубітом. Наприклад, в амплітудному кодуванні одна ознака може бути амплітудою стану , а інша — амплітудою стану . Загалом методи, що кодують у добуткових станах, дають більш дрібні схеми та можуть зберігати 1 або 2 ознаки на кожному кубіті. Методи, що використовують заплутаність та пов'язують ознаку зі станом, а не з кубітом, дають глибші схеми та в середньому можуть зберігати більше ознак на кубіт.
Проте кодування не обов'язково має бути повністю у добуткових або повністю у заплутаних станах, як в амплітудному кодуванні. Фактично багато схем кодування, вбудованих у Qiskit, дозволяють кодувати як до, так і після шару заплутання — на відміну від кодування лише на початку. Це відоме як «повторне завантаження даних» (data reuploading). Для ознайомлення з пов'язаними роботами дивись посилання [5] та [6].
У цьому розділі ми будемо використовувати та візуалізувати кілька вбудованих схем кодування. Усі методи в цьому розділі кодують ознак як повороти на параметризованих воротах на кубітах, де . Зверни увагу, що максимізація завантаження даних для заданої кількості кубітів — не єдиний критерій. У багатьох випадках глибина схеми може бути ще важливішим фактором, ніж кількість кубітів.
Efficient SU2
Поширений і корисний приклад кодування із заплутанням — схема Qiskit efficient_su2. Вражає те, що ця схема може, наприклад, кодувати 8 ознак лише на 2 кубітах. Подивимося на це і спробуємо зрозуміти, як це можливо.
from qiskit.circuit.library import efficient_su2
circuit = efficient_su2(num_qubits=2, reps=1, insert_barriers=True)
circuit.decompose().draw(output="mpl")

Записуючи стан, ми будемо дотримуватися конвенції Qiskit, де найменш значущі кубіти розташовуються праворуч, як у або Ці стани можуть дуже швидко ускладнюватися, і цей рідкісний приклад допомагає пояснити, чому такі стани рідко записують явно.
Наша система починається у стані До першого бар'єра (точка, яку ми позначаємо ) наші стани такі:
Це просто щільне кодування, яке ми вже бачили. Тепер після воріт CNOT, у другому бар'єрі (), наш стан такий:
Тепер застосовуємо останній набір однокубітних поворотів і збираємо подібні стани, щоб отримати:
Це, мабуть, важко розібрати. Натомість просто відступи назад і подумай, скільки параметрів ми завантажили у стан: вісім. При цьому у нас лише чотири обчислювальні базисні стани. На перший погляд може здатися, що ми завантажили більше параметрів, ніж має сенс, оскільки кінцевий стан можна записати як . Зверни увагу, однак, що кожен коефіцієнт є комплексним числом! У такому записі:
Видно, що у нас справді є вісім параметрів у стані, на яких можна закодувати вісім ознак.
Збільшуючи кількість кубітів і кількість повторень шарів заплутання та поворотів, можна кодувати значно більше даних. Явний запис хвильових функцій швидко стає нездійсненним. Але ми все ще можемо спостерігати кодування в дії.
Тут ми кодуємо вектор даних з 12 ознаками у 3-кубітну схему efficient_su2, використовуючи кожні з параметризованих воріт для кодування різних ознак.
У цьому векторі даних ознаки показані у певному порядку. Окремо від контексту не має значення, кодуються вони в цьому порядку чи у зворотному. Важливо відстежувати порядок і бути послідовним. Зверни увагу на схемі, що efficient_su2 передбачає певний порядок кодування: спочатку заповнюється перший шар параметризованих воріт від кубіта 0 до кубіта 2, а потім відбувається перехід до наступного шару. Це не є ані відповідним, ані невідповідним нотації з молодшим байтом (little-endian), оскільки тут порядок ознак даних не можна встановити за кубітом апріорі, до того як задано схему кодування.
x = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2]
circuit = efficient_su2(num_qubits=3, reps=1, insert_barriers=True)
encode = circuit.assign_parameters(x)
encode.decompose().draw(output="mpl")

Замість збільшення кількості кубітів можна збільшити кількість повторень шарів заплутання та поворотів. Але є межі корисності такої кількості повторень. Як уже зазначалося, існує компроміс: схеми з більшою кількістю кубітів або більшою кількістю повторень шарів заплутання та поворотів можуть зберігати більше параметрів, але це супроводжується збільшенням глибини схеми. Ми повернемося до глибин деяких вбудованих карт ознак далі. Кілька наступних методів кодування, вбудованих у Qiskit, містять у своїй назві словосполучення «карта ознак» (feature map). Повторимо: кодування даних у квантову схему і є відображенням ознак у тому сенсі, що воно переносить дані у новий простір — простір Гільберта задіяних кубітів. Відношення між розмірністю вихідного простору ознак і простором Гільберта залежатиме від схеми, яку ти використовуєш для кодування.
Карта ознак
Карта ознак (КОZ, Feature Map — ZFM) може бути інтерпретована як природне розширення фазового кодування. КОZ складається з чергуючих шарів однокубітних воріт: шарів воріт Адамара та шарів фазових воріт. Нехай вектор даних має ознак. Квантова схема, що виконує відображення ознак, подається у вигляді унітарного оператора, який діє на початковий стан:
де — -кубітний основний стан. Ця нотація використовується для узгодженості з посиланням [4] Havlicek et al. Ознаки даних відображаються один до одного з відповідними кубітами. Наприклад, якщо у векторі даних є 8 ознак, тоді використовується 8 кубітів. Схема КОZ складається з повторень підсхеми, що включає шари воріт Адамара та шари фазових воріт. Шар Адамара складається з воріт Адамара, що діють на кожен кубіт у -кубітному регістрі, , на одному й тому самому кроці алгоритму. Це описання також стосується шару фазових воріт, у якому на -й кубіт діють ворота . Кожні ворота мають одну ознаку як аргумент, але шар фазових воріт () є функцією вектора даних. Повний унітарний оператор схеми КОZ з одним повторенням такий:
Тоді повторень цього унітарного оператора дадуть:
Ознаки даних відображаються на фазові ворота однаково у всіх повтореннях. Стан карти ознак КОZ є добутковим станом і ефективно моделюється на класичному комп'ютері[4].
Для початку розглянемо невеликий приклад: двокубітна схема КОZ кодується за допомогою Qiskit і малюється, щоб показати просту структуру схеми. У прикладі реалізується одне повторення із вектором даних . Зверни увагу, що це записано у стандартному порядку вектора в Python, тобто -й елемент — це Ми можемо закодувати цю -у ознаку на -й кубіт або на -й. Знову ж таки, не завжди можна встановити єдине відображення 1:1 між порядком ознак і порядком кубітів, оскільки різні карти ознак кодують різну кількість ознак на кожен кубіт. Знову ж таки, важливо усвідомлювати, де кодується кожна ознака. При передачі списку параметрів до карти ознак вона кодуватиме ознаку 0 зі списку на найменш значущий кубіт із параметризованим вентилем, тобто на кубіт 0. Тому ми будемо дотримуватися цієї конвенції, роблячи це вручну. Ми закодуємо на -й кубіт, а — на -й кубіт.
Унітарний оператор схеми КОZ діє на початковий стан таким чином:
Формулу перегрупували навколо тензорного добутку, щоб підкреслити операції на кожному кубіті. Наведений нижче код Qiskit явно використовує ворота Адамара та фазові ворота, щоб показати структуру КОZ:
qc0 = QuantumCircuit(1)
qc1 = QuantumCircuit(1)
qc0.h(0)
qc0.p(pi / 2, 0)
qc1.h(0)
qc1.p(pi / 3, 0)
# Combine circuits qc0 and qc1 into 1 circuit
qc = QuantumCircuit(2)
qc.compose(qc0, [0], inplace=True)
qc.compose(qc1, [1], inplace=True)
qc.draw("mpl", scale=1)

Тепер закодуємо той самий вектор даних у схему КОZ з трьома повтореннями, , використовуючи клас Qiskit z_feature_map, що загалом дає нам квантову карту ознак . За замовчуванням у класі z_feature_map параметри множаться на 2 перед відображенням у фазові ворота: . Щоб відтворити ті самі кодування, що й вище, ділимо на 2.
from qiskit.circuit.library import z_feature_map
zfeature_map = z_feature_map(feature_dimension=2, reps=3)
zfeature_map = zfeature_map.assign_parameters([(1 / 2) * pi / 2, (1 / 2) * pi / 3])
zfeature_map.decompose().draw("mpl")

Очевидно, це інше відображення порівняно з ручним розрахунком вище, але зверни увагу на послідовність у порядку параметрів: знову закодовано на -й кубіт.
Ти можеш використовувати КОZ через клас ZFM у Qiskit; також можеш використовувати цю структуру як натхнення для побудови власного відображення ознак.
Карта ознак
Карта ознак (КOZZ, Feature Map — ZZFM) розширює КОZ, включаючи двокубітні заплутуючі ворота, а саме ворота -повороту . Вважається, що КOZZ загалом важко обчислити на класичному комп'ютері, на відміну від КОZ.
реалізує -взаємодію та є максимально заплутуючим при . можна розкласти у серію воріт на двох кубітах, як показано в наведеному нижче коді Qiskit із використанням ворота RZZ та методу класу QuantumCircuit — decompose. Ми кодуємо одну ознаку вектора даних :
qc = QuantumCircuit(2)
qc.rzz(pi, 0, 1)
qc.draw("mpl", scale=1)

Як це часто буває, ми бачимо це у вигляді єдиного вентиля, поки не використаємо .decompose(), щоб побачити всі складові ворота.
qc.decompose().draw("mpl", scale=1)

Дані відображаються за допомогою фазового повороту на другому кубіті. Ворота заплутують два кубіти, на які вони діють, зі ступенем заплутаності, що визначається значенням закодованої ознаки.
Повна схема КOZZ складається з воріт Адамара та фазових воріт, як у КОZ, після чого йде заплутання, описане вище. Одне повторення схеми КOZZ:
де містить шар ZZ-воріт, структурований за схемою заплутання. Кілька схем заплутання показано в блоках коду нижче. Структура також включає функцію, що комбінує ознаки даних кубітів, які заплутуються, таким чином. Скажімо, ворота застосовуються до кубітів і . У шарі фазових воріт на цих кубітах є фазові ворота, що кодують і відповідно. Аргумент воріт буде не просто однією з цих ознак чи іншою, а функцією, яку часто позначають (не плутати з азимутальним кутом):
Ми побачимо це в кількох прикладах нижче. Розширення на кілька повторень аналогічне випадку z_feature_map:
Оскільки оператори ускладнилися, спочатку закодуємо вектор даних з допомогою двокубітної КOZZ з одним повторенням, використовуючи такий код:
from qiskit.circuit.library import zz_feature_map
feature_dim = 2
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose(reps=1).draw("mpl", scale=1)

За замовчуванням у Qiskit ознаки відображаються разом у за допомогою цієї функції відображення: . Qiskit дозволяє користувачу налаштовувати функцію (або , де — множина пар кубітів, з'єднаних через ворота ) як крок попередньої обробки.
Переходячи до чотиривимірного вектора даних і відображення на чотирикубітну КOZZ з одним повторенням, ми можемо почати бачити відображення для різних пар кубітів. Також можна побачити значення «лінійного» заплутання:
feature_dim = 4
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose().draw("mpl", scale=1)

У схемі лінійного заплутання заплутуються найближчі сусідні (за нумерацією) пари кубітів у цій схемі. У Qiskit є інші вбудовані схеми заплутання, зокрема circular та full.
Карта ознак Паулі
Карта ознак Паулі (КОП, Pauli Feature Map — PFM) — це узагальнення КОZ і КOZZ до використання довільних воріт Паулі. Карта ознак Паулі має дуже схожу форму з двома попередніми картами ознак. Для повторень кодування ознак вектора :
Для КОП узагальнюється до унітарного оператора розкладу Паулі. Тут ми представляємо більш узагальнену форму розглянутих до цього часу карт ознак:
де — оператор Паулі, . Тут — множина всіх зв'язків між кубітами, визначених картою ознак, включаючи множину кубітів, на які діють однокубітні ворота. Тобто для карти ознак, у якій на кубіт 0 діють фазові ворота, а на кубіти 2 і 3 діють ворота , множина включатиме . пробігає по всіх елементах цієї множини. У попередніх картах ознак функція була пов'язана виключно або з однокубітними воротами, або виключно з двокубітними воротами. Тут ми визначаємо її в загальному вигляді:
Для документації дивись документацію класу Qiskit Pauli feature map). У КOZZ оператор обмежений .
Один зі способів зрозуміти наведений вище унітарний оператор — через аналогію з пропагатором у фізичній системі. Наведений вище унітарний оператор є оператором унітарної еволюції, , для гамільтоніана , подібного до моделі Ізінга, де часовий параметр замінено значеннями даних для керування еволюцією. Розклад цього унітарного оператора дає схему КОП. Зв'язки заплутання в можна інтерпретувати як ізінгові зв'язки у спіновій ґратці.
Розглянемо приклад з операторами Паулі та , що представляють ці ізінгові взаємодії. Qiskit надає клас pauli_feature_map для створення КОП з вибором однокубітних і -кубітних воріт, які в цьому прикладі передаватимуться як рядки Паулі 'Y' та 'XX'. Зазвичай дорівнює 1 або 2 для однокубітних та двокубітних взаємодій відповідно. Схема заплутання — «лінійна» (linear), тобто з'єднуються лише найближчі сусідні кубіти в квантовій схемі. Зверни увагу, що це не відповідає найближчим сусіднім кубітам на самому квантовому комп'ютері, оскільки ця квантова схема є рівнем абстракції.
from qiskit.circuit.library import pauli_feature_map
feature_dim = 3
pfmap = pauli_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1, paulis=["Y", "XX"]
)
pfmap.decompose().draw("mpl", scale=1.5)

Qiskit надає параметр у картах ознак Паулі для керування масштабуванням поворотів Паулі.
Стандартне значення дорівнює . Оптимізуючи його значення в інтервалі, наприклад, можна краще узгодити квантове ядро з даними.
Галерея карт ознак Паулі
Нижче ми візуалізуємо різні карти ознак Паулі для двокубітних схем, щоб краще уявити діапазон можливостей.
from qiskit.visualization import circuit_drawer
import matplotlib.pyplot as plt
feature_dim = 2
fig, axs = plt.subplots(9, 2)
i_plot = 0
for paulis in [
["I"],
["X"],
["Y"],
["Z"],
["XX"],
["XY"],
["XZ"],
["YY"],
["YZ"],
["ZZ"],
["X", "ZZ"],
["Y", "ZZ"],
["Z", "ZZ"],
["X", "YZ"],
["Y", "YZ"],
["Z", "YZ"],
["YY", "ZZ"],
["XY", "ZZ"],
]:
pfmap = pauli_feature_map(feature_dimension=feature_dim, paulis=paulis, reps=1)
circuit_drawer(
pfmap.decompose(),
output="mpl",
style={"backgroundcolor": "#EEEEEE"},
ax=axs[int((i_plot - i_plot % 2) / 2), i_plot % 2],
)
axs[int((i_plot - i_plot % 2) / 2), i_plot % 2].title.set_text(paulis)
i_plot += 1
fig.set_figheight(16)
fig.set_figwidth(16)
Наведене вище, звичайно, можна розширити, додавши інші перестановки та повторення матриць Паулі. Тебе заохочують поекспериментувати з цими варіантами.
Огляд вбудованих карт ознак
Ти познайомився з кількома схемами кодування даних у квантову схему:
- Базисне кодування
- Амплітудне кодування
- Кутове кодування
- Фазове кодування
- Щільне кодування
Ти бачив, як будувати власні карти ознак за допомогою цих схем кодування, а також розглянув чотири вбудовані карти ознак, які використовують кутове та фазове кодування:
- Efficient SU2
- Z feature map
- ZZ feature map
- Pauli feature map
Ці вбудовані карти ознак відрізнялися одна від одної в кількох аспектах:
- Глибина схеми для заданої кількості закодованих ознак
- Кількість кубітів, необхідних для заданої кількості ознак
- Ступінь заплутування (очевидно, пов'язаний з іншими відмінностями)
Код нижче застосовує ці чотири вбудовані карти ознак для кодування набору ознак і будує графік двокубітної глибини отриманої схеми. Оскільки частота помилок двокубітних вентилів значно вища, ніж однокубітних, найбільший інтерес може становити саме глибина двокубітних вентилів. У наведеному нижче коді ми отримуємо кількість усіх вентилів у схемі, спочатку розкладаючи схему, а потім використовуючи count_ops(). Тут двокубітні вентилі, які нас цікавлять, — це вентилі cx:
# Initializing parameters and empty lists for depths
x = [0.1, 0.2]
n_data = []
zz2gates = []
su22gates = []
z2gates = []
p2gates = []
# Generating feature maps
for n in range(3, 10):
x.append(n / 10)
zzcircuit = zz_feature_map(n, reps=1, insert_barriers=True)
zcircuit = z_feature_map(n, reps=1, insert_barriers=True)
su2circuit = efficient_su2(n, reps=1, insert_barriers=True)
pcircuit = pauli_feature_map(n, reps=1, paulis=["XX"], insert_barriers=True)
# Getting the cx depths
zzcx = zzcircuit.decompose().count_ops().get("cx")
zcx = zcircuit.decompose().count_ops().get("cx")
su2cx = su2circuit.decompose().count_ops().get("cx")
pcx = pcircuit.decompose().count_ops().get("cx")
# Appending the cx gate counts to the lists. We shift the zz and Pauli data points,
# because they overlap.
n_data.append(n)
zz2gates.append(zzcx - 0.5)
z2gates.append(0)
su22gates.append(su2cx)
p2gates.append(pcx + 0.5)
# Plot the output
plt.plot(n_data, p2gates, "bo")
plt.plot(n_data, zz2gates, "ro")
plt.plot(n_data, su22gates, "yo")
plt.plot(n_data, z2gates, "go")
plt.ylabel("CX Gates")
plt.xlabel("Data elements")
plt.legend(["Pauli", "ZZ", "SU2", "Z"])
# plt.suptitle('zz_feature_map(n)')
plt.show()
Загалом карти ознак Паулі та ZZ призводять до більшої глибини схеми й більшої кількості двокубітних вентилів порівняно з efficient_su2 та Z feature map.
Оскільки карти ознак, вбудовані в Qiskit, є широко застосовними, нам часто не потрібно проектувати власні, особливо на етапі навчання. Однак експерти з квантового машинного навчання, найімовірніше, повернуться до теми розробки власних карт ознак, коли зіткнуться з двома складними завданнями:
-
Сучасне залізо: наявність шуму й великі накладні витрати коду виправлення помилок означають, що сьогоднішні застосунки мають враховувати такі речі, як апаратна ефективність і мінімізація глибини двокубітних вентилів.
-
Відображення, що підходять до конкретного завдання: одна справа — сказати, що
zz_feature_map, наприклад, важко симулювати класично, а отже, вона є цікавою. Зовсім інша — щобzz_feature_mapідеально підходила саме твоєму завданню машинного навчання або набору даних. Продуктивність різних параметризованих квантових схем на різних типах даних є активною сферою досліджень.
Завершуємо нотаткою про апаратну ефективність.
Апаратно-ефективне відображення ознак
Апаратно-ефективне відображення ознак — це таке відображення, яке враховує обмеження реальних квантових комп'ютерів з метою зменшення шуму й помилок під час обчислень. При запуску квантових схем на квантових комп'ютерах найближчого покоління існує чимало стратегій зменшення шуму, притаманного залізу. Одна з основних стратегій апаратної ефективності — мінімізація глибини квантової схеми, щоб шум і декогеренція мали менше часу для спотворення обчислень. Глибина квантової схеми — це кількість вирівняних у часі кроків вентилів, необхідних для завершення всього обчислення (після оптимізації схеми)[5]. Пам'ятай, що глибина абстрактної логічної схеми може бути значно меншою, ніж глибина після транспіляції схеми для реального квантового комп'ютера.
Транспіляція — це процес перетворення квантової схеми з високорівневої абстракції у форму, готову до запуску на реальному квантовому комп'ютері, з урахуванням апаратних обмежень. Квантовий комп'ютер має власний набір однокубітних і двокубітних вентилів. Це означає, що всі вентилі в коді Qiskit мають бути транспільовані у набір нативних апаратних вентилів. Наприклад, в ibm_torino — QPU із процесором Heron r1, завершеним у 2023 році, — нативними або базисними вентилями є {CZ, ID, RZ, SX, X}. Це двокубітний вентиль controlled-Z і однокубітні вентилі: тотожність, -обертання, квадратний корінь із NOT і NOT відповідно, що утворюють універсальний набір. При реалізації багатокубітних вентилів як еквівалентних підсхем потрібні фізичні двокубітні вентилі , а також інші однокубітні вентилі, доступні в залізі. Крім того, для виконання двокубітного вентиля на парі фізично не з'єднаних кубітів додаються вентилі SWAP для переміщення станів між кубітами з метою забезпечення зв'язку, що неминуче подовжує схему. Для більшого контролю й можливості налаштування конвеєр транспілятора можна керувати за допомогою Qiskit Pass Manager. Докладніше про транспіляцію дивись у документації Qiskit Transpiler.
У роботі Havlicek et al. 2019 [2] одним із способів досягнення апаратної ефективності є використання карти ознак , оскільки вона є розкладом другого порядку (дивись розділ «Карта ознак » вище). Розклад -го порядку містить -кубітні вентилі. Квантові комп'ютери IBM® не мають нативних -кубітних вентилів при , тому для їхньої реалізації потрібен розклад на двокубітні вентилі CNOT, доступні в залізі. Другий спосіб мінімізації глибини — вибір топології зв'язків , яка безпосередньо відповідає зв'язкам архітектури. Додатково автори оптимізують роботу, орієнтуючись на більш продуктивну, відповідним чином з'єднану апаратну підсхему. Варто також розглянути мінімізацію кількості повторень карти ознак і вибір налаштованої низькоглибинної або «лінійної» схеми заплутування замість «повної», яка заплутує всі кубіти.

На наведеній вище графіці показано мережу вузлів і ребер, що відповідно представляють фізичні кубіти та апаратні зв'язки. Показано карту з'єднань і продуктивність ibm_torino з усіма можливими двокубітними вентилями зв'язку CZ. Кубіти кольорово закодовані за шкалою, що базується на часі релаксації T1 у мікросекундах (мкс), де більший час T1 є кращим і відображається світлішим відтінком. Ребра з'єднань кольорово закодовані за похибкою CZ, де темніші відтінки є кращими. Інформацію про специфікацію залізо можна отримати зі схеми конфігурації апаратного бекенду IBMQBackend.configuration().
Джерела
- Maria Schuld and Francesco Petruccione, Supervised Learning with Quantum Computers, Springer 2018, doi:10.1007/978-3-319-96424-9.
- Vojtech Havlicek et al., "Supervised Learning with Quantum Enhanced Feature Spaces." Nature, vol. 567 (2019): 209–212. https://arxiv.org/abs/1804.11326.
- Ryan LaRose and Brian Coyle, "Robust data encodings for quantum classifiers", Physical Review A 102, 032420 (2020), doi:10.1103/PhysRevA.102.032420, arXiv:2003.01695.
- Lou Grover and Terry Rudolph. "Creating Superpositions That Correspond to Efficiently Integrable Probability Distributions." arXiv:quant-ph/0208112, August 15, 2002, https://arxiv.org/abs/quant-ph/0208112.
- Adrián Pérez-Salinas, Alba Cervera-Lierta, Elies Gil-Fuster, José I. Latorre, "Data re-uploading for a universal quantum classifier", Quantum 4, 226 (2020), ArXiv.org/abs/1907.02085.
- Maria Schuld, Ryan Sweke, Johannes Jakob Meyer, "The effect of data encoding on the expressive power of variational quantum machine learning models", Phys. Rev. A 103, 032430 (2021), arxiv.org/abs/2008.08605
import qiskit
qiskit.version.get_version_info()