Квантова діагоналізація Крилова
У цьому уроці про квантову діагоналізацію Крилова (KQD) ми дамо відповіді на такі запитання:
- Що таке метод Крилова загалом?
- Чому метод Крилова працює і за яких умов?
- Яку роль відіграють квантові обчислення?
Квантова частина обчислень значною мірою ґрунтується на роботі з Ref [1].
Відеозапис нижче дає огляд методів Крилова в класичних обчисленнях, мотивує їх застосування та пояснює, яку роль у цьому процесі можуть відіграти квантові обчислення. Наступний текст містить детальніші пояснення й реалізує метод Крилова як класично, так і за допомогою квантового комп'ютера.
1. Вступ до методів Крилова
Метод підпростору Крилова може стосуватися будь-якого з кількох методів, побудованих навколо так званого підпростору Крилова. Повний огляд цих методів виходить за межі цього уроку, але Ref [2-4] може дати значно більше контексту. Тут ми зосередимося на тому, що таке підпростір Крилова, як і чому він корисний для розв'язання задач на власні значення, і нарешті — як його можна реалізувати на квантовому комп'ютері. Означення: Нехай задано симетричну, додатно напіввизначену матрицю . Простір Крилова порядку — це простір, натягнутий на вектори, отримані множенням вищих степенів матриці , аж до , на референтний вектор .
Хоча вектори вище натягують те, що ми називаємо підпростором Крилова, немає жодних підстав вважати, що вони будуть ортогональними. Зазвичай застосовується ітеративний процес ортонормалізації, схожий на ортогоналізацію Грама–Шмідта. Тут процес дещо відрізняється: кожен новий вектор ортогоналізується до решти в міру свого породження. У цьому контексті процес називається ітерацією Арнольді. Починаючи з початкового вектора , породжуємо наступний вектор , а потім забезпечуємо ортогональність цього другого вектора до першого, віднімаючи його проєкцію на . Тобто
Тепер легко бачити, що оскільки
Робимо те саме для наступного вектора, забезпечуючи його ортогональність до обох попередніх:
Якщо повторити цей процес для всіх векторів, отримаємо повний ортонормований базис для простору Крилова. Зауваж, що процес ортогоналізації дасть нуль, як тільки , оскільки ортогональних векторів неодмінно натягують увесь простір. Процес також дасть нуль, якщо будь-який вектор є власним вектором , — адже всі наступні вектори будуть кратні цьому вектору.
1.1 Простий приклад: метод Крилова «вручну»
Давай крок за кроком пройдемося побудовою підпростору Крилова на тривіально малій матриці, щоб наочно побачити процес. Почнімо з початкової матриці , що нас цікавить:
Для такого маленького прикладу власні вектори та власні значення можна легко знайти навіть вручну. Наведемо числове розв'язання.
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit qiskit-ibm-runtime scipy sympy
# One might use linalg.eigh here, but later matrices may not be Hermitian. So we use
# linalg.eig in this lesson.
import numpy as np
A = np.array([[4, -1, 0], [-1, 4, -1], [0, -1, 4]])
eigenvalues, eigenvectors = np.linalg.eig(A)
print("The eigenvalues are ", eigenvalues)
print("The eigenvectors are ", eigenvectors)
The eigenvalues are [2.58578644 4. 5.41421356]
The eigenvectors are [[ 5.00000000e-01 -7.07106781e-01 5.00000000e-01]
[ 7.07106781e-01 1.37464400e-16 -7.07106781e-01]
[ 5.00000000e-01 7.07106781e-01 5.00000000e-01]]
Запишемо їх тут для подальшого порівняння:
Нас цікавить, як цей процес працює (або дає збій) при збільшенні розмірності нашого підпростору Крилова . З цією метою застосуємо таку процедуру:
- Породжуємо підпростір повного векторного простору, починаючи з випадково обраного вектора (назвемо його , якщо він уже нормований, як вище).
- Проєктуємо повну матрицю на цей підпростір і знаходимо власні значення спроєктованої матриці .
- Збільшуємо розмір підпростору, породжуючи більше векторів і забезпечуючи їх ортонормованість за допомогою процедури, схожої на ортогоналізацію Грама–Шмідта.
- Проєктуємо на більший підпростір і знаходимо власні значення отриманої матриці .
- Повторюємо це, поки власні значення не зійдуться (або в цьому іграшковому випадку — поки не породимо вектори, що натягують повний векторний простір вихідної матриці ).
Зазвичай реалізація методу Крилова не потребує розв'язання задачі на власні значення для матриці, спроєктованої на кожний підпростір Крилова в міру його побудови. Можна побудувати підпростір потрібної розмірності, спроєктувати матрицю на цей підпростір і діагоналізувати спроєктовану матрицю. Проєктування і діагоналізація при кожній розмірності підпростору виконується лише для перевірки збіжності.
Розмірність :
Виберемо випадковий вектор, наприклад
Якщо він ще не нормований — нормуємо його.
Тепер проєктуємо нашу матрицю на підпростір цього одного вектора:
Це наша проєкція матриці на підпростір Крилова, коли він містить лише один вектор . Власне значення цієї матриці тривіально дорівнює 4. Це можна вважати нашою оцінкою нульового порядку для власних значень (в даному випадку лише одного) матриці . Хоча ця оцінка груба, вона правильна за порядком величини.
Розмірність :
Тепер породжуємо наступний вектор підпростору дією на попередній вектор:
Тепер відніміємо проєкцію цього вектора на попередній вектор, щоб забезпечити ортогональність.
Якщо він ще не нормований — нормуємо. У цьому випадку вектор уже нормований, тому
Тепер проєктуємо матрицю A на підпростір цих двох векторів:
Все одно лишається задача знаходження власних значень цієї матриці. Але ця матриця дещо менша за повну. У задачах, що стосуються дуже великих матриць, робота з таким меншим підпростором може бути надзвичайно вигідною.
Хоча це все ще не дуже точна оцінка, вона краща за оцінку нульового порядку. Проведемо ще одну ітерацію, щоб процес став зрозумілішим. Проте це підривало б сенс методу, адже на наступній ітерації нам доведеться діагоналізувати матрицю 3×3, тобто ми не зекономимо ні часу, ні обчислювальних ресурсів.
Розмірність :
Тепер породжуємо наступний вектор підпростору дією A на попередній вектор:
Тепер відніміємо проєкцію цього вектора на обидва попередніх вектори, щоб забезпечити ортогональність.
Якщо він ще не нормований — нормуємо. У цьому випадку вектор уже нормований, тому
Тепер проєктуємо матрицю на підпростір цих векторів:
Тепер знаходимо власні значення:
Ці власні значення точно збігаються з власними значеннями вихідної матриці . Так і має бути, адже ми розширили наш підпростір Крилова до розміру, що охоплює весь векторний простір вихідної матриці .
У цьому прикладі метод Крилова може не видаватися особливо простішим за пряму діагоналізацію. Справді, як ми побачимо в наступних розділах, метод Крилова вигідний лише, починаючи з певної розмірності матриці; цей приклад призначений для того, щоб допомогти нам розв'язувати задачі на власні значення/власні вектори для надзвичайно великих матриць.
Це єдиний приклад, розв'язаний «вручну», але розділ 2 нижче містить обчислювальні приклади.
Уточнення термінів
Поширена помилка — вважати, що для заданої задачі існує лише один підпростір Крилова. Але оскільки є багато початкових векторів, до яких можна застосувати нашу матрицю, існує й багато можливих підпросторів Крилова. Словосполучення «the Krylov subspace» (певний підпростір Крилова) ми вживатимемо лише для позначення конкретного підпростору Крилова, вже визначеного для конкретного прикладу. У загальних підходах до розв'язання задач ми говоритимемо про «a Krylov subspace» (деякий підпростір Крилова). Насамкінець уточнимо: правомірно говорити про «простір Крилова». Часто його називають «підпростором Крилова», бо він використовується у контексті проєктування матриць із початкового простору в підпростір. Дотримуючись цього контексту, ми здебільшого й надалі називатимемо його підпростором.
Перевір своє розуміння
Поясни, чому розширювати розмірність підпростору Крилова понад розмірність матриці (а) не корисно і (б) неможливо.
Відповідь
(a) Оскільки ми ортонормалізуємо вектори в процесі їх породження, набір з таких векторів утворює повний базис, тобто будь-який вектор у просторі можна виразити їх лінійною комбінацією. (b) Процес ортогоналізації полягає у відніманні проєкції нового вектора на всі попередні вектори. Якщо всі попередні вектори натягують увесь векторний простір, то відніманням проєкцій на повний підпростір завжди отримуємо нульовий вектор.
Уяви, що колега-дослідник демонструє метод Крилова на маленькій іграшковій матриці для кількох колег. Він планує використати матрицю та початковий вектор:
і
Чи є тут якась проблема? Як би ти порадив(-ла) колезі?
Відповідь
Твій(-оя) колега випадково обрав(-ла) власний вектор як початковий. Дія матриці на початковий вектор просто повертає той самий вектор, помножений на власне значення. Це не породжуватиме підпростір зростаючої розмірності. Порадь колезі обрати інший початковий вектор, переконавшись, що він не є власним.
Застосуй метод Крилова до наведеної нижче матриці, вибравши відповідний новий початковий вектор. Запиши оцінки мінімального власного значення для 0-го та 1-го порядків підпростору Крилова.
Відповідь
Існує багато можливих відповідей залежно від вибору початкового вектора. Оберемо:
Щоб отримати , застосовуємо один раз до , а потім робимо ортогональним до
Оцінка 0-го порядку — проєкція на наш підпростір Крилова:
Оцінка 1-го порядку — проєкція на цей підпростір Крилова:
Це можна зробити вручну, але найзручніше — за допомогою numpy:
import numpy as np
vstar = np.array([[1/np.sqrt(3),1/np.sqrt(3),1/np.sqrt(3)],[-1/np.sqrt(6),np.sqrt(2/3),-1/np.sqrt(6)]]
)
A = np.array([[1, 1, 0],
[1, 1, 1],
[0, 1, 1]])
v = np.array([[1/np.sqrt(3),-1/np.sqrt(6)],[1/np.sqrt(3),np.sqrt(2/3)],[1/np.sqrt(3),-1/np.sqrt(6)]])
proj = vstar@A@v
print(proj)
eigenvalues, eigenvectors = np.linalg.eig(proj)
print("The eigenvalues are ", eigenvalues)
print("The eigenvectors are ", eigenvectors)
виводить:
[[ 2.33333333 0.47140452]
[ 0.47140452 -0.33333333]]
The eigenvalues are [ 2.41421356 -0.41421356]
The eigenvectors are [[ 0.98559856 -0.16910198]
[ 0.16910198 0.98559856]]
Мінімальна оцінка власного значення: -0.414.
1.2 Типи методів Крилова
«Методи підпростору Крилова» можуть стосуватися будь-якого з кількох ітеративних методів, що використовуються для розв'язання великих лінійних систем і задач на власні значення. Спільне між ними — побудова наближеного розв'язку з підпростору Крилова
де — початкове наближення (див. Ref [5]). Методи відрізняються тим, як вони обирають найкраще наближення з цього підпростору, балансуючи між такими факторами, як швидкість збіжності, використання пам'яті та загальна обчислювальна вартість. Мета цього уроку — використання квантових обчислень у контексті методів підпростору Крилова; вичерпне обговорення цих методів виходить за його межі. Короткі означення нижче наведені виключно для контексту та містять посилання для подальшого вивчення цих методів.
Метод спряжених градієнтів (CG): Цей метод використовується для розв'язання симетричних, додатно визначених лінійних систем [6]. Він мінімізує -норму похибки на кожній ітерації, що робить його особливо ефективним для систем, що виникають при дискретизації еліптичних рівнянь у частинних похідних [7]. Ми використаємо цей підхід у наступному розділі, щоб мотивувати, чому підпростір Крилова є ефективним підпростором для пошуку покращених розв'язків лінійних систем.
Метод узагальненого мінімального нев'язка (GMRES): Призначений для розв'язання загальних несиметричних лінійних систем. Мінімізує норму нев'язка на підпросторі Крилова при кожній ітерації, що робить його надійним, але потенційно ресурсомістким за пам'яттю для великих систем [7].
Метод мінімального нев'язка (MINRES): Використовується для розв'язання симетричних невизначених лінійних систем. Схожий на GMRES, але використовує симетрію матриці для зниження обчислювальної вартості [8].
Серед інших варто відзначити метод повної ортогоналізації (FOM), тісно пов'язаний з методом Арнольді для задач на власні значення, метод бі-спряжених градієнтів (BiCG) та метод редукції індукованої розмірності (IDR).
1.3 Чому метод підпростору Крилова працює
Тут ми обґрунтуємо, що метод підпростору Крилова є ефективним способом наближеного обчислення власних значень матриці через ітеративне уточнення наближень власних векторів — крізь призму найшвидшого спуску. Ми доведемо, що за наявності початкового наближення основного стану простір послідовних поправок до цього наближення, що забезпечує найшвидшу збіжність, — це саме підпростір Крилова. Ми не ставимо за мету строгий доказ поведінки збіжності.
Припустимо, що наша матриця симетрична і додатно визначена. Це робить наш аргумент найбільш релевантним для методу CG вище. Ми не висуваємо жодних припущень щодо розрідженості; також не стверджуємо, що обов'язково має бути ермітовою (що потрібно, якщо вона є гамільтоніаном).
Зазвичай ми хочемо розв'язати задачу виду
Можна уявити, що , де — деяка стала, як у задачі на власні значення. Але наше формулювання задачі поки що залишається загальнішим.
Починаємо з вектора , що є наближеним розв'язком. Хоча є паралелі між цим наближенням і з розділу 1.1, тут ми їх не використовуємо. Наше наближення має похибку, яку ми називаємо
Також визначаємо нев'язок
Тут ми використовуємо велику літеру , щоб відрізнити нев'язок від розмірності підпростору Крилова .

Тепер хочемо зробити крок корекції вигляду
сподіваючись покращити наше наближення. Тут — деякий вектор, що поки що не визначений. Нехай — похибка після корекції. Тоді

Нас цікавить, як поводиться наша похибка після перетворення матрицею. Тому обчислимо -норму похибки:
де ми використали симетрію та те, що Тут — деяка стала, що не залежить від . Як згадувалося в розділі 1.2, -норма похибки — не єдина величина, яку можна мінімізувати, але вона є хорошим вибором. Ми хочемо дослідити, як ця величина залежить від нашого вибору векторів корекції Тому визначаємо функцію :
— це лише похибка як функція корекції , виміряна в -нормі. Отже, ми хочемо обрати так, щоб була якомога меншою. З цією метою обчислимо градієнт . Використовуючи симетрію :
Градієнт вказує у напрямку найшвидшого зростання, а отже, протилежний напрямок — це напрямок найшвидшого спуску, тобто найшвидшого зменшення функції: напрямок найшвидшого спуску. У нашому початковому наближенні , де , маємо: Отже, функція найшвидше зменшується у напрямку нев'язка Тому наш початковий крок найбільш виграє від додавання вектора для деякого скаляра .
На наступному кроці знову обираємо вектор і додаємо його до поточного наближення. За тим самим аргументом обираємо для деякого скаляра . Продовжуємо таким чином, так що -та ітерація нашого вектора:
Еквівалентно, ми хочемо нарощувати простір, з якого обираємо покращені оцінки, послідовно додаючи , і т.д. -й оцінений вектор лежить у
Тепер, використовуючи співвідношення
бачимо, що
Тобто простір, який ми нарощуємо і який найефективніше наближає правильний розв'язок , — це саме простір, утворений послідовними діями матриці на Підпростір Крилова і є простором, натягнутим на вектори послідовних напрямків найшвидшого спуску.
На завершення нагадаємо, що ми не робили жодних кількісних тверджень про масштабування цього підходу і не обговорювали порівняльну перевагу для розріджених матриць. Це лише мотивація до застосування методів підпростору Крилова й спроба додати їм інтуїтивного сенсу. Тепер дослідимо поведінку цих методів чисельно.
Перевір своє розуміння
У наведеному вище процесі ми запропонували мінімізувати -норму похибки. Які ще величини можна розглядати для мінімізації при пошуку основного стану та його власного значення?
Відповідь
Можна уявити використання вектора нев'язка замість -норми похибки. Можуть бути випадки, коли розгляд самого вектора похибки є корисним.
2. Методи Крилова в класичних обчисленнях
У цьому розділі ми реалізуємо ітерації Арнольді програмно, щоб скористатися підпростором Крилова для розв'язання задач на власні значення. Спочатку застосуємо це до невеликого прикладу, а потім розглянемо, як час обчислень масштабується зі збільшенням розміру матриці. Ключова ідея полягає в тому, що генерація векторів, що охоплюють простір Крилова, є основним внеском у загальний час обчислень. Обсяг необхідної пам'яті варіюється залежно від конкретного методу Крилова, але обмеження пам'яті можуть стримувати застосування традиційних методів Крилова.
2.1 Простий невеликий приклад
Під час побудови підпростору Крилова нам потрібно ортонормалізувати вектори нашого підпростору. Визначимо функцію, яка приймає вже наявний вектор підпростору vknown (не обов'язково нормований) і вектор-кандидат для додавання до підпростору vnext, робить vnext ортогональним до vknown і нормалізованим. Також визначимо функцію, що проходить цей процес для всіх наявних векторів підпростору Крилова, забезпечуючи повністю ортонормований набір.
# vknown is some established vector in our subspace. vnext is one we wish to add,
# which must be orthogonal to vknown.
def orthog_pair(vknown, vnext):
vknown = vknown / np.sqrt(vknown.T @ vknown)
diffvec = vknown.T @ vnext * vknown
vnext = vnext - diffvec
return vnext
# v is the candidate vector to be added to our subspace. s is the existing subspace.
def orthoset(v, s):
v = v / np.sqrt(v.T @ v)
temp = v
for i in range(len(s)):
temp = orthog_pair(s[i], temp)
v = temp / np.sqrt(temp.T @ temp)
return v
Тепер визначимо функцію, яка ітеративно будує дедалі більший підпростір Крилова, доки простір векторів Крилова не охопить весь простір вихідної матриці. Це дозволить побачити, наскільки добре власні значення, отримані методом підпростору Крилова, збігаються з точними значеннями в залежності від розміру підпростору Крилова. Важливо, що наша функція krylov_full_build повертає вектори Крилова, проєктовані гамільтоніани, власні значення та необхідний час.
# Necessary imports and definitions to track time in microseconds
import time
def time_mus():
return int(time.time() * 1000000)
# This function constructs a Krylov subspace that spans the whole space of the original matrix.
# Input:
# v0 : initial vector
# matrix : original matrix to be diagonalized
# Output:
# ks : Krylov vectors
# Hs : projected Hamiltonians
# eigs : eigenvalues
# k_tot_times : time required for the operation
def krylov_full_build(v0, matrix):
t0 = time_mus()
b = v0 / np.sqrt(v0 @ v0.T)
A = matrix
ks = []
ks.append(b)
Hs = []
eigs = []
Hs.append(b.T @ A @ b)
eigs.append(np.array([b.T @ A @ b]))
k_tot_times = []
for j in range(len(A) - 1):
vec = A @ ks[j].T
ortho = orthoset(vec, ks)
ks.append(ortho)
ksarray = np.array(ks)
Hs.append(ksarray @ A @ ksarray.T)
eigs.append(np.linalg.eig(Hs[j + 1]).eigenvalues)
k_tot_times.append(time_mus() - t0)
# Return the Krylov vectors, the projected Hamiltonians, the eigenvalues,
# and the total time required.
return (ks, Hs, eigs, k_tot_times)
Перевіримо це на матриці, яка все ще досить мала, але більша за ту, що зручно обчислювати вручну.
# Define our small test matrix
test_matrix = np.array(
[
[4, -1, 0, 1, 0],
[-1, 4, -1, 2, 1],
[0, -1, 4, 3, 3],
[1, 2, 3, 4, 0],
[0, 1, 3, 0, 4],
]
)
# Give the test matrix and an initial guess as arguments in the function defined above.
# Calculate outputs.
test_ks, test_Hs, test_eigs, text_k_tot_times = krylov_full_build(
np.array([0.5, 0.5, 0, 0.5, 0.5]), test_matrix
)
Перевіримо наші функції, переконавшись, що на останньому кроці (коли простір Крилова є повним векторним простором вихідної матриці) власні значення методу Крилова точно збігаються з результатами точного числового діагоналізування:
print(np.linalg.eig(test_matrix).eigenvalues)
print(test_eigs[len(test_matrix) - 1])
[-1.36956923 8.43756009 2.9040308 5.34436028 4.68361806]
[-1.36956923 8.43756009 2.9040308 4.68361806 5.34436028]
Чудово. Звісно, головне — наскільки гарне наше наближення залежно від розміру підпростору Крилова. Оскільки нас часто цікавить пошук основних станів та інших мінімальних власних значень (а також через інші, більш алгебраїчні причини, описані нижче), розглянемо нашу оцінку найменшого власного значення як функцію розміру підпростору Крилова. Тобто
def errors(matrix, krylov_eigs):
targ_min = min(np.linalg.eig(matrix).eigenvalues)
err = []
for i in range(len(matrix)):
err.append(min(krylov_eigs[i]) - targ_min)
return err
import matplotlib.pyplot as plt
krylov_error = errors(test_matrix, test_eigs)
plt.plot(krylov_error)
plt.axhline(y=0, color="red", linestyle="--") # Add dashed red line at y=0
plt.xlabel("Order of Krylov subspace") # Add x-axis label
plt.ylabel("Error in minimum eigenvalue") # Add y-axis label
plt.show()
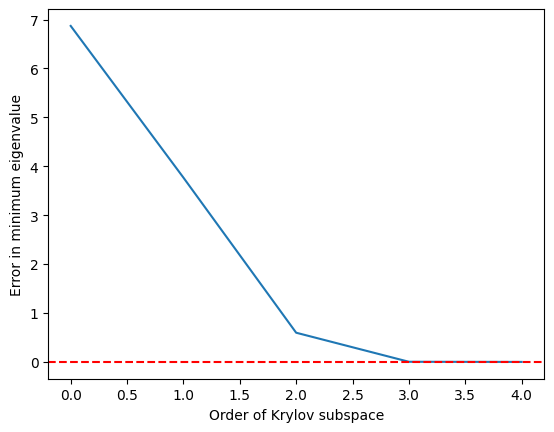
Бачимо, що мінімальне власне значення досягається досить точно, щойно підпростір Крилова зростає до а за збіг стає ідеальним.
2.2 Масштабування часу зі зростанням розміру матриці
Переконаємось, що метод Крилова може бути вигіднішим за точні числові солвери власних значень у такий спосіб:
- Побудуємо випадкові матриці (не розріджені, це не ідеальне застосування для KQD)
- Визначимо власні значення двома методами: безпосередньо за допомогою NumPy та за допомогою підпростору Крилова.
- Обираємо поріг точності власних значень, нижче якого приймаємо оцінки Крилова.
- Порівняємо астрономічний час, необхідний для розв'язання двома способами.
Застереження: Як докладно обговорюється нижче, квантове діагоналізування Крилова найкраще застосовувати до операторів, матричні подання яких є розрідженими та/або можуть бути записані через невелику кількість груп операторів Паулі, що комутують. Випадкові матриці, які ми тут використовуємо, не відповідають цьому опису. Вони корисні лише для дослідження масштабу, на якому класичні методи Крилова можуть бути корисними. По-друге, під час застосування методу Крилова ми обчислюватимемо власні значення для підпросторів Крилова різних розмірів. Будемо реєструвати час для мінімального підпростору Крилова, який досягає необхідної точності для власного значення основного стану. Знову ж таки, це дещо відрізняється від розв'язання задачі, яка є нерозв'язуваною для точних солверів, оскільки ми використовуємо точний розв'язок для визначення необхідного розміру підпростору.
Починаємо з генерації набору випадкових матриць.
import numpy as np
# Set the random seed
np.random.seed(42)
# how many random matrices will we make
num_matrix = 200
matrices = []
for m in range(1, num_matrix):
matrices.append(np.random.rand(m, m))
Тепер діагоналізуємо кожну матрицю безпосередньо за допомогою numpy. Вимірюємо час, необхідний для діагоналізації, для подальшого порівняння.
matrix_numpy_times = []
matrix_numpy_eigs = []
for mm in range(num_matrix - 1):
t0 = time_mus()
matrix_numpy_eigs.append(min(np.linalg.eig(matrices[mm]).eigenvalues))
matrix_numpy_times.append(time_mus() - t0)
plt.plot(matrix_numpy_times)
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (microsec)") # Add y-axis label
plt.show()
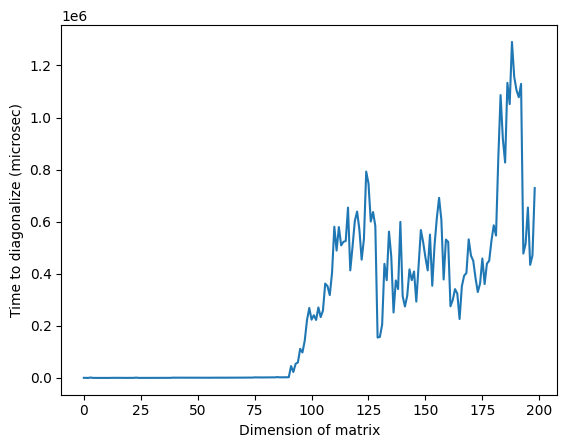
Зверни увагу, що на зображенні вище аномально великий час приблизно при розмірі 125 може бути зумовлений випадковою природою матриць або особливостями реалізації на класичному процесорі, але цей ефект не є відтворюваним. Повторний запуск коду дасть інший профіль з іншими аномальними піками.
Тепер для кожної матриці будемо поступово нарощувати підпростір Крилова і обчислювати власні значення крок за кроком. На кожному кроці перевіряємо, чи отримано найменше власне значення з точністю до заданої абсолютної похибки. Підпростір мінімального розміру, що задовольняє цю умову, є підпростором, для якого ми записуємо час обчислень. Виконання цієї комірки може зайняти кілька хвилин залежно від швидкості процесора. Можна пропустити виконання або зменшити максимальний розмір матриць, що діагоналізуються. Попередньо обчислені результати цілком достатні для розуміння.
# Choose the absolute error you can tolerate, and make a list for tracking the Krylov subspace size
# at which that error is achieved.
abserr = 0.05
accept_subspace_size = []
# Lists to store total time spent on the Krylov method, and the subset of that time spent on
# diagonalizing the projected matrix.
matrix_krylov_tot_times = []
matrix_krylov_dim = []
# Step through all our random matrices
for mm in range(0, num_matrix - 1):
test_ks, test_Hs, test_eigs, test_k_tot_times = krylov_full_build(
np.ones(len(matrices[mm])), matrices[mm]
)
# We have not yet found a Krylov subspace that produces our minimum eigenvalue to
# within the required error.
found = 0
for j in range(0, len(matrices[mm]) - 1):
# If we still haven't found the desired subspace...
if found == 0:
# ...but if this one satisfies the requirement, then record everything
if (
abs((min(test_eigs[j]) - matrix_numpy_eigs[mm]) / matrix_numpy_eigs[mm])
< abserr
):
accept_subspace_size.append(j)
matrix_krylov_tot_times.append(test_k_tot_times[j])
matrix_krylov_dim.append(mm)
found = 1
Побудуємо графік часів, отриманих двома методами, для порівняння:
plt.plot(matrix_numpy_times, color="blue")
plt.plot(matrix_krylov_dim, matrix_krylov_tot_times, color="green")
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (microsec)") # Add y-axis label
plt.show()

Це фактичні виміряні часи, але для зручності обговорення згладимо ці криві, усереднивши по кількох сусідніх точках / розмірах матриць. Це зроблено нижче:
smooth_numpy_times = []
smooth_krylov_times = []
# Choose the number of adjacent points over which to average forward;
# the same will be used backward.
smooth_steps = 10
# We will do this smoothing for all points/matrix dimensions
for i in range(len(matrix_krylov_tot_times)):
# Ensure we don't exceed the boundaries of our lists
start = max(0, i - smooth_steps)
end = min(len(matrix_krylov_tot_times) - 1, i + smooth_steps)
# Dummy variables for accumulating an average over adjacent points. This is done for both Krylov
# and the NumPy calculations.
smooth_count = 0
smooth_numpy_sum = 0
smooth_krylov_sum = 0
for j in range(start, end):
smooth_numpy_sum = smooth_numpy_sum + matrix_numpy_times[j]
smooth_krylov_sum = smooth_krylov_sum + matrix_krylov_tot_times[j]
smooth_count = smooth_count + 1
# Appending the averaged adjacent values to our new smooth lists
smooth_numpy_times.append(smooth_numpy_sum / smooth_count)
smooth_krylov_times.append(smooth_krylov_sum / smooth_count)
plt.plot(smooth_numpy_times, color="blue")
plt.plot(smooth_krylov_times, color="green")
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (smoothed, microsec)") # Add y-axis label
plt.show()

Зверни увагу, що час, необхідний для побудови підпростору Крилова, спочатку перевищує час, потрібний для повного діагоналізування numpy. Але зі збільшенням розміру матриці метод Крилова стає вигіднішим. Це справедливо навіть при зниженні допустимої похибки, однак перевага починається при більших розмірах матриці. Це варто розібрати детальніше.
Часова складність числового діагоналізування — (з деякою варіацією між алгоритмами). Часова складність генерації ортонормованого базису з векторів також є . Отже, перевага методу Крилова не пов'язана з використанням якогось ортонормованого базису, а саме з використанням конкретного ортонормованого базису, який ефективно виділяє власні значення, що нас цікавлять. Ми вже бачили це зі схеми доведення в першому розділі цього уроку, і це критично важливо для гарантій збіжності в методах Крилова. Підсумуємо досягнуте:
- Для дуже великих матриць метод підпростору Крилова може давати наближені власні значення в межах необхідних допусків швидше, ніж традиційні алгоритми діагоналізування.
- Для таких дуже великих матриць генерація підпростору Крилова є найбільш часозатратною частиною методу підпростору Крилова.
- Таким чином, ефективний спосіб генерації підпростору Крилова мав би величезну цінність. І саме тут на сцену виходить квантовий комп'ютер.
Перевір своє розуміння
Зверни увагу на згладжений графік часів діагоналізації залежно від розміру матриці вище.
(a) При приблизно якому розмірі матриці метод Крилова став швидшим за цим графіком?
(b) Які аспекти обчислень могли б змінити цей розмір матриці, при якому метод Крилова стає швидшим?
Відповідь
(a) Відповіді можуть відрізнятися при повторному запуску, але метод Крилова стає швидшим приблизно при розмірі 80–85.
(b) Є багато можливих відповідей. Деякі важливі фактори — це необхідна точність і розрідженість матриць, що діагоналізуються.
3. Кріловський підхід через часову еволюцію
Усе, що ми описали досі, можна зробити класично. Тож як і коли ми б використовували квантовий комп'ютер? Для дуже великих матриць метод Крилова може вимагати тривалого часу обчислень і великої кількості пам'яті. Час для матричної операції над масштабується як у найгіршому випадку. Навіть множення розріджених матриць на вектор (типовий випадок для класичних солверів типу Крилова) має часову складність . Це виконується для кожного вектора, який ми хочемо мати в нашому підпросторі. Розмір підпростору зазвичай не є значною часткою і часто масштабується як . Отже, генерація всіх векторів масштабується як у найгіршому випадку. Хоча є й інші кроки, такі як ортогоналізація, це домінуюче масштабування, яке слід мати на увазі.
Квантові обчислення дозволяють нам змінити, які атрибути задачі визначають масштабування часу та ресурсів. Замість залежності від розміру матриці скрізь, ми побачимо такі речі, як кількість вимірювань (shots) і кількість некомутуючих термів Паулі, що складають гамільтоніан. Розберемося, як це працює.
3.1 Часова еволюція
Нагадаємо, що оператор часової еволюції квантового стану — це (і дуже поширено, особливо в квантових обчисленнях, опускати з нотації). Один зі способів зрозуміти і навіть реалізувати таку показникову функцію від оператора — розглянути її розклад у ряд Тейлора. Зверни увагу, що ця операція, діючи на деякий початковий вектор , дає суму членів зі зростаючими степенями , що застосовані до початкового стану. Схоже, ми можемо просто побудувати наш підпростір Крилова, застосовуючи часову еволюцію до нашого початкового стану-здогадки!
Складність полягає в реалізації часової еволюції на реальному квантовому комп'ютері. Багато членів гамільтоніана не комутуватимуть один з одним. Тому, хоча деякі прості показникові оператори, як-от , відповідають простим схемам, загальні гамільтоніани — ні. А оскільки вони містять некомутуючі члени, ми не можемо просто розкласти показниковий на добуток простих, як це можна робити з числами.
Це непросто, але цей процес добре вивчений у квантових обчисленнях. Ми проводимо часову еволюцію на квантових комп'ютерах за допомогою процесу, що називається трот терізацією, яка сама по собі є багатою темою[10]. Але на дуже високому рівні, розбиваючи часову еволюцію на дуже маленькі кроки, скажімо кроків розміром , ми обмежуємо вплив некомутативності членів.
де .
Назвемо підпростір Крилова порядку r, побудований у класичному контексті безпосередньо через степені H, «степеневим підпростором Крилова».
Тепер ми будуємо аналогічний простір за допомогою унітарного оператора часової еволюції ; назвемо його «унітарним простором Крилова» . Степеневий підпростір Крилова , який ми використовуємо класично, не може бути побудований безпосередньо на квантовому комп'ютері, оскільки не є унітарним оператором. Можна довести, що використання унітарного підпростору Крилова дає аналогічні гарантії збіжності, що й степеневий підпростір Крилова: а саме, похибка основного стану ефективно збігається за умови, що початковий стан має перекриття з істинним основним станом, яке не є експоненційно малим, і за умови достатнього зазору між власними значеннями. Більш точне обговорення збіжності дивись у Ref [1].
Тут степені перетворюються на різні кроки часу (-й степінь відповідає кроку вперед на час ). Позначимо елемент підпростору, що пройшов часову еволюцію на загальний час , як .
Ми можемо проєктувати наш гамільтоніан H на унітарний підпростір Крилова . Іншими словами, обчислюємо кожен матричний елемент у базисі . Назвемо цю проєктовану матрицю .
3.2 Як реалізувати на квантовому комп'ютері
Матричні елементи задаються значеннями очікування , які можна оцінити за допомогою квантового комп'ютера. Майте на увазі, що можна записати як суму операторів Паулі на різних кубітах, і не всі оператори Паулі можна вимірювати одночасно. Ми можемо відсортувати члени Паулі в групи комутуючих членів і виміряти всі одразу. Але може знадобитися багато таких груп, щоб охопити всі члени. Тому стає важливою кількість різних груп, що комутують між собою, на які можна розбити члени, .
Тут — рядок Паулі вигляду або набір таких рядків Паулі, що комутують один з одним. Враховуючи, що ми можемо записати як таку суму вимірюваних операторів, наступні вирази для матричних елементів можна реалізувати за допомогою примітиву Qiskit Runtime Estimator.
Де — вектори унітарного простору Крилова, а — кратні кроку часу . На квантовому комп'ютері обчислення кожного матричного елемента можна виконати будь-яким алгоритмом, що дозволяє отримати перекриття між квантовими станами. У цьому уроці ми зосередимось на тесті Адамара. Оскільки має розмірність , проєктований у підпростір гамільтоніан матиме розміри . При достатньо малому (зазвичай достатньо для отримання збіжних оцінок власних значень) ми можемо легко діагоналізувати проєктований гамільтоніан класично. Однак ми не можемо безпосередньо діагоналізувати через неортогональність векторів простору Крилова. Нам потрібно виміряти їхні перекриття і побудувати матрицю
Це дозволяє розв'язати задачу на власні значення в неортогональному просторі (також звану узагальненою задачею на власні значення):
Після цього можна отримати оцінки власних значень і власних станів , розглянувши розв'язки цієї узагальненої задачі. Наприклад, оцінка енергії основного стану отримується як найменше власне значення , а основний стан — з відповідного власного вектора . Коефіцієнти в визначають внесок різних векторів, що охоплюють .
Узагальнена задача на власні значення
Чому ми не можемо просто діагоналізувати ? Оскільки містить інформацію про геометрію базису Крилова (який є неортогональним в усіх, окрім дуже особливих, випадках), сам по собі не описує проєкцію повного гамільтоніана, тому його власні значення не мають жодного особливого зв'язку з власними значеннями повного гамільтоніана — вони можуть бути будь-якими випадковими значеннями. Розв'язання узагальненої задачі на власні значення є необхідним для отримання наближених власних значень і власних векторів, що відповідають проєкції повного гамільтоніана на простір Крилова.
На малюнку показано схемне представлення модифікованого тесту Адамара — методу для обчислення перекриття між різними квантовими станами. Для кожного матричного елемента виконується тест Адамара між станами та . Це підкреслено на малюнку колірною схемою для матричних елементів і відповідних операцій , . Таким чином, для обчислення всіх матричних елементів проєктованого гамільтоніана потрібен набір тестів Адамара для всіх можливих комбінацій векторів простору Крилова. Верхній дріт у схемі тесту Адамара — це допоміжний кубіт (анцила), що вимірюється або в базисі X, або Y; його значення очікування визначає значення перекриття між станами. Нижній дріт представляє всі кубіти системного гамільтоніана. Операція готує системний кубіт у стан , керований станом анцили (аналогічно для ), а операція представляє розклад Паулі системного гамільтоніана . Реалізація цього на квантовому комп'ютері показана детальніше нижче.
4. Квантове діагоналізування Крилова на квантовому комп'ютері
Тепер ми реалізуємо квантове діагоналізування Крилова на реальному квантовому комп'ютері. Почнімо з імпорту корисних пакетів.
import numpy as np
import scipy as sp
import matplotlib.pylab as plt
from typing import Union, List
import warnings
from qiskit.quantum_info import SparsePauliOp, Pauli
from qiskit.circuit import Parameter
from qiskit import QuantumCircuit, QuantumRegister
from qiskit.circuit.library import PauliEvolutionGate
from qiskit.synthesis import LieTrotter
# from qiskit.providers.fake_provider import Fake20QV1
from qiskit_ibm_runtime import QiskitRuntimeService, EstimatorV2 as Estimator, Batch
import itertools as it
warnings.filterwarnings("ignore")
Нижче ми визначаємо функцію для розв'язання узагальненої задачі на власні значення, яку щойно описали.
def solve_regularized_gen_eig(
h: np.ndarray,
s: np.ndarray,
threshold: float,
k: int = 1,
return_dimn: bool = False,
) -> Union[float, List[float]]:
"""
Method for solving the generalized eigenvalue problem with regularization
Args:
h (numpy.ndarray):
The effective representation of the matrix in our Krylov subspace
s (numpy.ndarray):
The matrix of overlaps between vectors of our Krylov subspace
threshold (float):
Cut-off value for the eigenvalue of s
k (int):
Number of eigenvalues to return
return_dimn (bool):
Whether to return the size of the regularized subspace
Returns:
lowest k-eigenvalue(s) that are the solution of the regularized generalized eigenvalue problem
"""
s_vals, s_vecs = sp.linalg.eigh(s)
s_vecs = s_vecs.T
good_vecs = np.array([vec for val, vec in zip(s_vals, s_vecs) if val > threshold])
h_reg = good_vecs.conj() @ h @ good_vecs.T
s_reg = good_vecs.conj() @ s @ good_vecs.T
if k == 1:
if return_dimn:
return sp.linalg.eigh(h_reg, s_reg)[0][0], len(good_vecs)
else:
return sp.linalg.eigh(h_reg, s_reg)[0][0]
else:
if return_dimn:
return sp.linalg.eigh(h_reg, s_reg)[0][:k], len(good_vecs)
else:
return sp.linalg.eigh(h_reg, s_reg)[0][:k]
Принаймні на початкових етапах тестування корисно знати точний класичний розв'язок для перевірки поведінки збіжності. Функція нижче обчислює енергію основного стану гамільтоніана, приймаючи як аргументи гамільтоніан і кількість кубітів.
def single_particle_gs(H_op, n_qubits):
"""
Find the ground state of the single particle(excitation) sector
"""
H_x = []
for p, coeff in H_op.to_list():
H_x.append(set([i for i, v in enumerate(Pauli(p).x) if v]))
H_z = []
for p, coeff in H_op.to_list():
H_z.append(set([i for i, v in enumerate(Pauli(p).z) if v]))
H_c = H_op.coeffs
print("n_sys_qubits", n_qubits)
n_exc = 1
sub_dimn = int(sp.special.comb(n_qubits + 1, n_exc))
print("n_exc", n_exc, ", subspace dimension", sub_dimn)
few_particle_H = np.zeros((sub_dimn, sub_dimn), dtype=complex)
sparse_vecs = [
set(vec) for vec in it.combinations(range(n_qubits + 1), r=n_exc)
] # list all of the possible sets of n_exc indices of 1s in n_exc-particle states
m = 0
for i, i_set in enumerate(sparse_vecs):
for j, j_set in enumerate(sparse_vecs):
m += 1
if len(i_set.symmetric_difference(j_set)) <= 2:
for p_x, p_z, coeff in zip(H_x, H_z, H_c):
if i_set.symmetric_difference(j_set) == p_x:
sgn = ((-1j) ** len(p_x.intersection(p_z))) * (
(-1) ** len(i_set.intersection(p_z))
)
else:
sgn = 0
few_particle_H[i, j] += sgn * coeff
gs_en = min(np.linalg.eigvalsh(few_particle_H))
print("single particle ground state energy: ", gs_en)
return gs_en
4.1 Крок 1: Відображення задачі на квантові схеми та оператори
Тепер визначимо гамільтоніан. Він відрізняється від функції вище тим, що та функція приймає гамільтоніан як аргумент і повертає лише основний стан — і робить це класично. Гамільтоніан, який ми визначаємо тут, задає енергетичні рівні всіх власних енергетичних станів, і його можна побудувати за допомогою операторів Паулі та реалізувати на квантовому комп'ютері.
Ми обираємо гамільтоніан, що відповідає ланцюжку спінів, які можуть мати будь-яку орієнтацію в просторі — так звана «ланцюжок Гайзенберга». Ми припускаємо, що спін може зазнавати впливу лише від найближчих сусідів ( та спінів), але не від більш віддалених. Ми також допускаємо можливість того, що взаємодія між спінами відрізняється залежно від того, вздовж яких осей вони спрямовані. Така асиметрія іноді виникає, наприклад, через структуру кристалічної гратки, в яку вбудовані спіни.
# Define problem Hamiltonian.
n_qubits = 10
# coupling strength for XX, YY, and ZZ interactions
JX = 1
JY = 3
JZ = 2
# Define the Hamiltonian:
H_int = [["I"] * n_qubits for _ in range(3 * (n_qubits - 1))]
for i in range(n_qubits - 1):
H_int[i][i] = "Z"
H_int[i][i + 1] = "Z"
for i in range(n_qubits - 1):
H_int[n_qubits - 1 + i][i] = "X"
H_int[n_qubits - 1 + i][i + 1] = "X"
for i in range(n_qubits - 1):
H_int[2 * (n_qubits - 1) + i][i] = "Y"
H_int[2 * (n_qubits - 1) + i][i + 1] = "Y"
H_int = ["".join(term) for term in H_int]
H_tot = [
(term, JZ)
if term.count("Z") == 2
else (term, JY)
if term.count("Y") == 2
else (term, JX)
for term in H_int
]
# Get operator
H_op = SparsePauliOp.from_list(H_tot)
print(H_tot)
[('ZZIIIIIIII', 2), ('IZZIIIIIII', 2), ('IIZZIIIIII', 2), ('IIIZZIIIII', 2), ('IIIIZZIIII', 2), ('IIIIIZZIII', 2), ('IIIIIIZZII', 2), ('IIIIIIIZZI', 2), ('IIIIIIIIZZ', 2), ('XXIIIIIIII', 1), ('IXXIIIIIII', 1), ('IIXXIIIIII', 1), ('IIIXXIIIII', 1), ('IIIIXXIIII', 1), ('IIIIIXXIII', 1), ('IIIIIIXXII', 1), ('IIIIIIIXXI', 1), ('IIIIIIIIXX', 1), ('YYIIIIIIII', 3), ('IYYIIIIIII', 3), ('IIYYIIIIII', 3), ('IIIYYIIIII', 3), ('IIIIYYIIII', 3), ('IIIIIYYIII', 3), ('IIIIIIYYII', 3), ('IIIIIIIYYI', 3), ('IIIIIIIIYY', 3)]
Код нижче обмежує гамільтоніан одночастинковими станами та використовує спектральну норму для вибору відповідного розміру кроку за часом . Ми евристично вибираємо значення dt (на основі верхніх меж норми гамільтоніана). Посилання [9] показало, що достатньо малий часовий крок — це , і що до певної міри краще недооцінювати це значення, ніж переоцінювати, оскільки переоцінка може дозволити внескам від висококенергетичних станів зіпсувати навіть оптимальний стан у просторі Крилова. З іншого боку, надто малий призводить до гіршої обумовленості підпростору Крилова, оскільки базисні вектори Крилова менше відрізняються від кроку до кроку.
# Get Hamiltonian restricted to single-particle states
single_particle_H = np.zeros((n_qubits, n_qubits))
for i in range(n_qubits):
for j in range(i + 1):
for p, coeff in H_op.to_list():
p_x = Pauli(p).x
p_z = Pauli(p).z
if all(p_x[k] == ((i == k) + (j == k)) % 2 for k in range(n_qubits)):
sgn = ((-1j) ** sum(p_z[k] and p_x[k] for k in range(n_qubits))) * (
(-1) ** p_z[i]
)
else:
sgn = 0
single_particle_H[i, j] += sgn * coeff
for i in range(n_qubits):
for j in range(i + 1, n_qubits):
single_particle_H[i, j] = np.conj(single_particle_H[j, i])
# Set dt according to spectral norm
dt = np.pi / np.linalg.norm(single_particle_H, ord=2)
dt
np.float64(0.17453292519943295)
Вкажемо кількість кроків Троттера у часовій еволюції, а також максимальну розмірність простору Крилова — 4. Ця розмірність простору Крилова недостатня для реальних застосувань, але достатня для цього прикладу. Крім того, ми перевірятимемо збіжність при ще менших розмірностях. У пізніших уроках ми дослідимо методи, які дозволяють масштабувати та проектувати гамільтоніани на більші підпростори.
# Set parameters for quantum Krylov algorithm
krylov_dim = 4 # size of krylov subspace
num_trotter_steps = 4
dt_circ = dt / num_trotter_steps
Підготовка стану
Оберемо референсний стан , що має певне перекриття з основним станом. Для цього гамільтоніана ми використовуємо стан зі збудженням на середньому кубіті як референсний стан.
qc_state_prep = QuantumCircuit(n_qubits)
qc_state_prep.x(int(n_qubits / 2) + 1)
qc_state_prep.draw("mpl", scale=0.5)

Часова еволюція
Ми можемо реалізувати оператор часової еволюції, породжений заданим гамільтоніаном: , через апроксимацію Лі–Троттера. Для простоти використовуємо вбудований PauliEvolutionGate у схемі часової еволюції. Загальний синтаксис виглядає так.
t = Parameter("t")
## Create the time-evo op circuit
evol_gate = PauliEvolutionGate(
H_op, time=t, synthesis=LieTrotter(reps=num_trotter_steps)
)
qr = QuantumRegister(n_qubits)
qc_evol = QuantumCircuit(qr)
qc_evol.append(evol_gate, qargs=qr)
<qiskit.circuit.instructionset.InstructionSet at 0x7ccaa4664250>
Нижче ми використаємо цю схему в тесті Адамара, виконуючи кроки вперед за часом .
Тест Адамара
Нагадаємо, що нам потрібно обчислити матричні елементи як , так і матриці Грама за допомогою тесту Адамара. Розглянемо, як це працює в нашому контексті, зосередившись спочатку на побудові Загальний процес показано графічно нижче. Шари кольорових блоків підготовки стану нагадують, що цей процес виконується для всіх комбінацій та у нашому підпросторі.
Стани системи на вказаних кроках:
Тут — це член Паулі у розкладі гамільтоніана (зауваж, що він не може бути лінійною комбінацією кількох комутуючих членів Паулі, оскільки це не було б унітарним — групування можливе за допомогою іншої конструкції, яку ми покажемо пізніше); , — контрольовані операції, що готують вектори , унітарного простору Крилова, де . Вимірювання та на цій схемі дають, відповідно, дійсну та уявну частини потрібних матричних елементів.
Починаючи з кроку 4, застосуємо вентиль Адамара до нульового кубіта.
Тоді вимірюємо або .
З тотожності . Аналогічно, вимірювання дає
Додавши ці кроки до часової еволюції, налаштованої раніше, запишемо наступне.
## Create the time-evo op circuit
evol_gate = PauliEvolutionGate(
H_op, time=dt, synthesis=LieTrotter(reps=num_trotter_steps)
)
## Create the time-evo op dagger circuit
evol_gate_d = PauliEvolutionGate(
H_op, time=dt, synthesis=LieTrotter(reps=num_trotter_steps)
)
evol_gate_d = evol_gate_d.inverse()
# Put pieces together
qc_reg = QuantumRegister(n_qubits)
qc_temp = QuantumCircuit(qc_reg)
qc_temp.compose(qc_state_prep, inplace=True)
for _ in range(num_trotter_steps):
qc_temp.append(evol_gate, qargs=qc_reg)
for _ in range(num_trotter_steps):
qc_temp.append(evol_gate_d, qargs=qc_reg)
qc_temp.compose(qc_state_prep.inverse(), inplace=True)
# Create controlled version of the circuit
controlled_U = qc_temp.to_gate().control(1)
# Create hadamard test circuit for real part
qr = QuantumRegister(n_qubits + 1)
qc_real = QuantumCircuit(qr)
qc_real.h(0)
qc_real.append(controlled_U, list(range(n_qubits + 1)))
qc_real.h(0)
print("Circuit for calculating the real part of the overlap in S via Hadamard test")
qc_real.draw("mpl", fold=-1, scale=0.5)
Circuit for calculating the real part of the overlap in S via Hadamard test

Ми вже попереджали про глибину, пов'язану зі схемами Троттера. Виконання тесту Адамара за таких умов може давати ще глибші схеми, особливо після розкладу до нативних вентилів. Це зросте ще більше, якщо врахувати топологію пристрою. Тому, перш ніж використовувати час на квантовому комп'ютері, варто перевірити двокубітну глибину нашої схеми.
print(
"Number of layers of 2Q operations",
qc_real.decompose(reps=2).depth(lambda x: x[0].num_qubits == 2),
)
Number of layers of 2Q operations 14401
Схема такої глибини не може повертати корисні результати на сучасних квантових комп'ютерах. Якщо ми хочемо побудувати та , нам потрібен кращий підхід. Саме для цього нижче вводиться ефективний тест Адамара.
4.2 Крок 2. Оптимізація схем та операторів для цільового апаратного забезпечення
Ефективний тест Адамара
Ми можемо оптимізувати глибокі схеми для тесту Адамара, вводячи деякі апроксимації та спираючись на певні припущення щодо модельного гамільтоніана. Наприклад, розглянемо таку схему для тесту Адамара:
Припустимо, що ми можемо класично обчислити — власне значення під дією гамільтоніана . Це виконується, коли гамільтоніан зберігає симетрію U(1). Хоча це може здаватися сильним припущенням, є багато випадків, де можна безпечно вважати, що існує вакуумний стан (у нашому випадку він відповідає стану ), на який дія гамільтоніана не впливає. Це справедливо, наприклад, для хімічних гамільтоніанів, що описують стабільну молекулу (де кількість електронів зберігається). З урахуванням того, що вентиль готує бажаний референсний стан , наприклад, для підготовки стану Хартрі–Фока у хімії — це добуток одно-кубітних NOT, тому контрольований — це просто добуток CNOT. Тоді наведена вище схема реалізує такий стан перед вимірюванням:
де ми використали класично симульований фазовий зсув під час переходу від кроку 2 до кроку 3. Тому математичні сподівання є
Завдяки цим припущенням нам вдалося записати математичні сподівання операторів інтересу з меншою кількістю контрольованих операцій. Фактично, нам потрібно реалізувати лише контрольовану підготовку стану , а не контрольовані часові еволюції. Переформулювання нашого обчислення, як показано вище, дозволить значно зменшити глибину отриманих схем.
Варто зауважити, що як додатковий бонус: оскільки оператор Паулі тепер з'являється як вимірювання в кінці схеми, а не як контрольований вентиль посередині, його можна вимірювати разом з іншими комутуючими операторами Паулі, як у розкладі наведеному вище.
Розклад оператора часової еволюції через декомпозицію Троттера
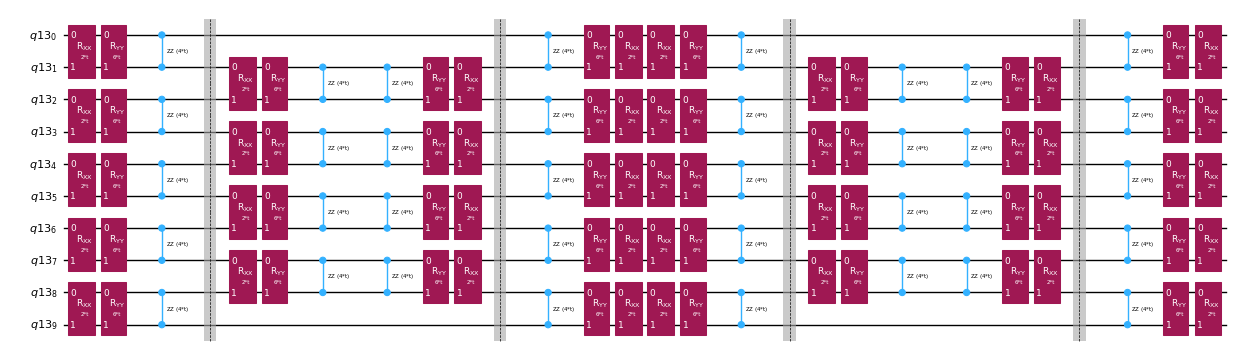
Замість точної реалізації оператора часової еволюції можна використати декомпозицію Троттера для реалізації його апроксимації. Багаторазове повторення декомпозиції Троттера певного порядку дозволяє ще більше зменшити похибку апроксимації. Нижче ми безпосередньо будуємо реалізацію Троттера найбільш ефективним способом для графу взаємодій розглянутого нами гамільтоніана (лише взаємодії між найближчими сусідами). На практиці ми вставляємо обертання Паулі , , з параметризованим кутом , що відповідають апроксимованій реалізації . Через різницю у визначенні обертань Паулі та часової еволюції, яку ми намагаємося реалізувати, доведеться використати параметр , щоб отримати часову еволюцію на . Крім того, ми змінюємо порядок операцій на непарних повтореннях кроків Троттера, що функціонально еквівалентно, але дозволяє синтезувати суміжні операції в єдиний унітарний оператор . Це дає значно дрібнішу схему, ніж та, що отримується за допомогою стандартного PauliEvolutionGate().
t = Parameter("t")
# Create instruction for rotation about XX+YY-ZZ:
Rxyz_circ = QuantumCircuit(2)
Rxyz_circ.rxx(2 * JX * t, 0, 1)
Rxyz_circ.ryy(2 * JY * t, 0, 1)
Rxyz_circ.rzz(2 * JZ * t, 0, 1)
Rxyz_instr = Rxyz_circ.to_instruction(label="R J_x XX + J_y YY + J_z ZZ")
interaction_list = [
[[i, i + 1] for i in range(0, n_qubits - 1, 2)],
[[i, i + 1] for i in range(1, n_qubits - 1, 2)],
] # linear chain
qr = QuantumRegister(n_qubits)
trotter_step_circ = QuantumCircuit(qr)
for i, color in enumerate(interaction_list):
for interaction in color:
trotter_step_circ.append(Rxyz_instr, interaction)
if i < len(interaction_list) - 1:
trotter_step_circ.barrier()
reverse_trotter_step_circ = trotter_step_circ.reverse_ops()
qc_evol = QuantumCircuit(qr)
for step in range(num_trotter_steps):
if step % 2 == 0:
qc_evol = qc_evol.compose(trotter_step_circ)
else:
qc_evol = qc_evol.compose(reverse_trotter_step_circ)
qc_evol.decompose().draw("mpl", fold=-1, scale=0.5)
Знову підготуємо початковий стан для цього ефективного тесту Адамара.
control = 0
excitation = int(n_qubits / 2) + 1
controlled_state_prep = QuantumCircuit(n_qubits + 1)
controlled_state_prep.cx(control, excitation)
controlled_state_prep.draw("mpl", fold=-1, scale=0.5)

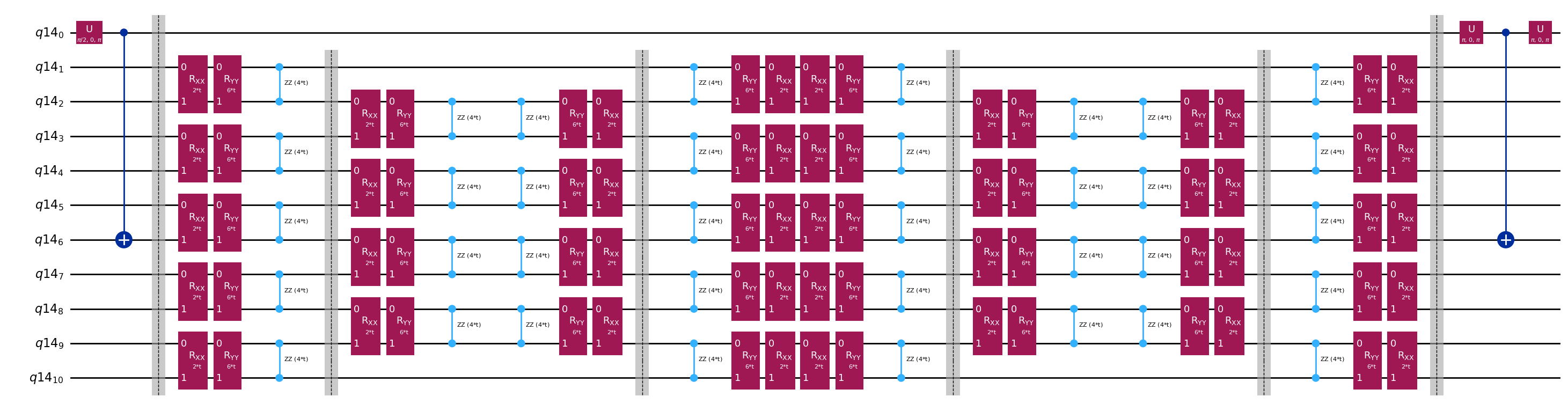
Шаблонні схеми для обчислення матричних елементів та через тест Адамара
Єдина відмінність між схемами, що використовуються в тесті Адамара, — це фаза в операторі часової еволюції та вимірювані спостережувані. Тому ми можемо підготувати шаблонну схему, що представляє загальну схему для тесту Адамара, з місцями-заповнювачами для вентилів, які залежать від оператора часової еволюції.
# Parameters for the template circuits
parameters = []
for idx in range(1, krylov_dim):
parameters.append(dt_circ * (idx))
# Create modified hadamard test circuit
qr = QuantumRegister(n_qubits + 1)
qc = QuantumCircuit(qr)
qc.h(0)
qc.compose(controlled_state_prep, list(range(n_qubits + 1)), inplace=True)
qc.barrier()
qc.compose(qc_evol, list(range(1, n_qubits + 1)), inplace=True)
qc.barrier()
qc.x(0)
qc.compose(controlled_state_prep.inverse(), list(range(n_qubits + 1)), inplace=True)
qc.x(0)
qc.decompose().draw("mpl", fold=-1)
print(
"The optimized circuit has 2Q gates depth: ",
qc.decompose().decompose().depth(lambda x: x[0].num_qubits == 2),
)
The optimized circuit has 2Q gates depth: 50
Ця глибина суттєво менша порівняно з оригінальним тестом Адамара. Вона є прийнятною для сучасних квантових комп'ютерів, хоча все ще досить велика. Нам знадобиться застосувати найсучасніше пом'якшення помилок, щоб отримати корисні результати.
Оберемо бекенд для виконання нашого квантового обчислення Крилова, щоб можна було транспілювати схему для запуску на цьому квантовому комп'ютері.
# Use the least-busy backend or specify a quantum computer using the syntax commented out below.
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
# Or you may choose a specify backend and channel if necessary for your workflow.
# service = QiskitRuntimeService(channel="ibm_quantum_platform")
# backend = service.backend("ibm_fez")
Тепер транспілюємо наші схеми та оператори.
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
target = backend.target
basis_gates = list(target.operation_names)
pm = generate_preset_pass_manager(
optimization_level=3, backend=backend, basis_gates=basis_gates
)
qc_trans = pm.run(qc)
print(qc_trans.depth(lambda x: x[0].num_qubits == 2))
print(qc_trans.count_ops())
qc_trans.draw("mpl", fold=-1, idle_wires=False, scale=0.5)
36
OrderedDict([('rz', 410), ('sx', 361), ('cz', 156), ('x', 18), ('barrier', 6)])

Після оптимізації двокубітна глибина транспільованої схеми ще більше зменшилась.
4.3 Крок 3. Виконання за допомогою примітиву Qiskit Runtime
Тепер створимо PUB-и для виконання за допомогою Estimator.
# Define observables to measure for S
observable_S_real = "I" * (n_qubits) + "X"
observable_S_imag = "I" * (n_qubits) + "Y"
observable_op_real = SparsePauliOp(
observable_S_real
) # define a sparse pauli operator for the observable
observable_op_imag = SparsePauliOp(observable_S_imag)
layout = qc_trans.layout # get layout of transpiled circuit
observable_op_real = observable_op_real.apply_layout(
layout
) # apply physical layout to the observable
observable_op_imag = observable_op_imag.apply_layout(layout)
observable_S_real = (
observable_op_real.paulis.to_labels()
) # get the label of the physical observable
observable_S_imag = observable_op_imag.paulis.to_labels()
observables_S = [[observable_S_real], [observable_S_imag]]
# Define observables to measure for H
# Hamiltonian terms to measure
observable_list = []
for pauli, coeff in zip(H_op.paulis, H_op.coeffs):
# print(pauli)
observable_H_real = pauli[::-1].to_label() + "X"
observable_H_imag = pauli[::-1].to_label() + "Y"
observable_list.append([observable_H_real])
observable_list.append([observable_H_imag])
layout = qc_trans.layout
observable_trans_list = []
for observable in observable_list:
observable_op = SparsePauliOp(observable)
observable_op = observable_op.apply_layout(layout)
observable_trans_list.append([observable_op.paulis.to_labels()])
observables_H = observable_trans_list
# Define a sweep over parameter values
params = np.vstack(parameters).T
# Estimate the expectation value for all combinations of
# observables and parameter values, where the pub result will have
# shape (# observables, # parameter values).
pub = (qc_trans, observables_S + observables_H, params)
Схеми для можна обчислити класично. Зробимо це, перш ніж переходити до випадку з використанням квантового комп'ютера.
from qiskit.quantum_info import StabilizerState, Pauli
qc_cliff = qc.assign_parameters({t: 0})
# Get expectation values from experiment
S_expval_real = StabilizerState(qc_cliff).expectation_value(
Pauli("I" * (n_qubits) + "X")
)
S_expval_imag = StabilizerState(qc_cliff).expectation_value(
Pauli("I" * (n_qubits) + "Y")
)
# Get expectation values
S_expval = S_expval_real + 1j * S_expval_imag
H_expval = 0
for obs_idx, (pauli, coeff) in enumerate(zip(H_op.paulis, H_op.coeffs)):
# Get expectation values from experiment
expval_real = StabilizerState(qc_cliff).expectation_value(
Pauli(pauli[::-1].to_label() + "X")
)
expval_imag = StabilizerState(qc_cliff).expectation_value(
Pauli(pauli[::-1].to_label() + "Y")
)
expval = expval_real + 1j * expval_imag
# Fill-in matrix elements
H_expval += coeff * expval
print(H_expval)
(10+0j)
Хоча нам вдалося суттєво зменшити глибину схеми завдяки ефективному тесту Адамара, глибина все ще достатня, щоб вимагати передових методів пом'якшення помилок. Нижче ми вказуємо атрибути методів пом'якшення, що використовуються. Всі застосовані методи важливі, але окремо варто відзначити probabilistic error amplification (PEA). Ця потужна техніка потребує значних квантових ресурсів. Обчислення, що виконується тут, може займати 20 хвилин і більше на реальному квантовому комп'ютері. Можеш поекспериментувати з параметрами нижче, щоб збільшити або зменшити точність і, відповідно, накладні витрати. Стандартні налаштування нижче дають результати з високою точністю.
# Experiment options
num_randomizations = 300
num_randomizations_learning = 20
max_batch_circuits = 20
shots_per_randomization = 100
learning_pair_depths = [0, 4, 24]
noise_factors = [1, 1.3, 1.6]
# Base option formatting
options = {
# Builtin resilience settings for ZNE
"resilience": {
"measure_mitigation": True,
"zne_mitigation": True,
"zne": {"noise_factors": noise_factors},
# TREX noise learning configuration
"measure_noise_learning": {
"num_randomizations": num_randomizations_learning,
"shots_per_randomization": shots_per_randomization,
},
# PEA noise model configuration
"layer_noise_learning": {
"max_layers_to_learn": 10,
"layer_pair_depths": learning_pair_depths,
"shots_per_randomization": shots_per_randomization,
"num_randomizations": num_randomizations_learning,
},
},
# Randomization configuration
"twirling": {
"num_randomizations": num_randomizations,
"shots_per_randomization": shots_per_randomization,
"strategy": "all",
},
# Experimental settings for PEA method
"experimental": {
# # Just in case, disable any further qiskit transpilation not related to twirling / DD
# "skip_transpilation": True,
# Execution configuration
"execution": {
"max_pubs_per_batch_job": max_batch_circuits,
"fast_parametric_update": True,
},
# Error Mitigation configuration
"resilience": {
# ZNE Configuration
"zne": {
"amplifier": "pea",
"return_all_extrapolated": True,
"return_unextrapolated": True,
"extrapolated_noise_factors": [0] + noise_factors,
}
},
},
}
Нарешті, виконуємо схеми для і за допомогою Estimator.
# This job required 17 minutes of QPU time to run on a Heron r2 processor. This is only an estimate.
# Your execution time may vary.
with Batch(backend=backend) as batch:
# Estimator
estimator = Estimator(mode=batch, options=options)
job = estimator.run([pub], precision=1)
4.4 Крок 4. Постобробка та аналіз результатів
Від квантового комп'ютера ми отримали окремі матричні елементи та комутуючі групи Паулі, що утворюють матричні елементи . Ці члени необхідно об'єднати, щоб відновити наші матриці та розв'язати узагальнену задачу на власні значення.
# Store the outputs as 'results'.
results = job.result()[0]
Обчислення ефективного гамільтоніана та матриць перекривання
Спершу обчислимо фазу, накопичену станом під час некерованої еволюції в часі.
prefactors = [
np.exp(-1j * sum([c for p, c in H_op.to_list() if "Z" in p]) * i * dt)
for i in range(1, krylov_dim)
]
Маючи результати виконання схем, можна виконати постобробку даних і обчислити матричні елементи .
# Assemble S, the overlap matrix of dimension D:
S_first_row = np.zeros(krylov_dim, dtype=complex)
S_first_row[0] = 1 + 0j
# Add in ancilla-only measurements:
for i in range(krylov_dim - 1):
# Get expectation values from experiment
expval_real = results.data.evs[0][0][i] # automatic extrapolated evs if ZNE is used
expval_imag = results.data.evs[1][0][i] # automatic extrapolated evs if ZNE is used
# Get expectation values
expval = expval_real + 1j * expval_imag
S_first_row[i + 1] += prefactors[i] * expval
S_first_row_list = S_first_row.tolist() # for saving purposes
S_circ = np.zeros((krylov_dim, krylov_dim), dtype=complex)
# Distribute entries from first row across matrix:
for i, j in it.product(range(krylov_dim), repeat=2):
if i >= j:
S_circ[j, i] = S_first_row[i - j]
else:
S_circ[j, i] = np.conj(S_first_row[j - i])
from sympy import Matrix
Matrix(S_circ)
А також матричні елементи :
import itertools
# Assemble S, the overlap matrix of dimension D:
H_first_row = np.zeros(krylov_dim, dtype=complex)
H_first_row[0] = H_expval
for obs_idx, (pauli, coeff) in enumerate(zip(H_op.paulis, H_op.coeffs)):
# Add in ancilla-only measurements:
for i in range(krylov_dim - 1):
# Get expectation values from experiment
expval_real = results.data.evs[2 + 2 * obs_idx][0][
i
] # automatic extrapolated evs if ZNE is used
expval_imag = results.data.evs[2 + 2 * obs_idx + 1][0][
i
] # automatic extrapolated evs if ZNE is used
# Get expectation values
expval = expval_real + 1j * expval_imag
H_first_row[i + 1] += prefactors[i] * coeff * expval
H_first_row_list = H_first_row.tolist()
H_eff_circ = np.zeros((krylov_dim, krylov_dim), dtype=complex)
# Distribute entries from first row across matrix:
for i, j in itertools.product(range(krylov_dim), repeat=2):
if i >= j:
H_eff_circ[j, i] = H_first_row[i - j]
else:
H_eff_circ[j, i] = np.conj(H_first_row[j - i])
from sympy import Matrix
Matrix(H_eff_circ)
Нарешті, можна розв'язати узагальнену задачу на власні значення для :
і отримати оцінку енергії основного стану :
gnd_en_circ_est_list = []
for d in range(1, krylov_dim + 1):
# Solve generalized eigenvalue problem
gnd_en_circ_est = solve_regularized_gen_eig(
H_eff_circ[:d, :d], S_circ[:d, :d], threshold=1e-1
)
gnd_en_circ_est_list.append(gnd_en_circ_est)
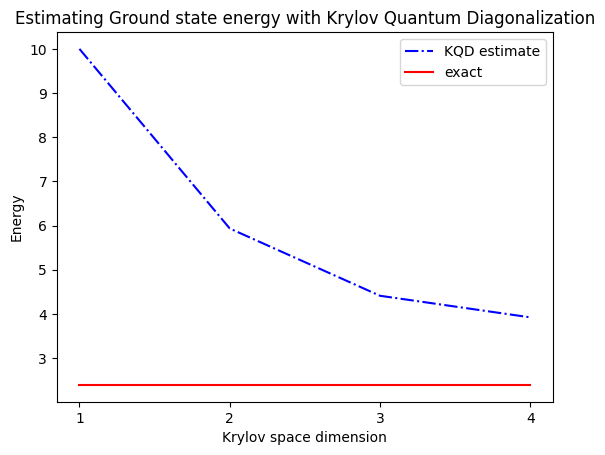
print("The estimated ground state energy is: ", gnd_en_circ_est)
The estimated ground state energy is: 10.0
The estimated ground state energy is: 5.933953916292923
The estimated ground state energy is: 4.4101773995740645
The estimated ground state energy is: 3.921288588521255
Для сектора з однією частинкою ми можемо ефективно обчислити основний стан цього сектора гамільтоніана класично.
gs_en = single_particle_gs(H_op, n_qubits)
n_sys_qubits 10
n_exc 1 , subspace dimension 11
single particle ground state energy: 2.391547869638771
len(H_op)
27
plt.plot(
range(1, krylov_dim + 1),
gnd_en_circ_est_list,
color="blue",
linestyle="-.",
label="KQD estimate",
)
plt.plot(
range(1, krylov_dim + 1),
[gs_en] * krylov_dim,
color="red",
linestyle="-",
label="exact",
)
plt.xticks(range(1, krylov_dim + 1), range(1, krylov_dim + 1))
plt.legend()
plt.xlabel("Krylov space dimension")
plt.ylabel("Energy")
plt.title("Estimating Ground state energy with Krylov Quantum Diagonalization")
plt.show()
5. Обговорення та розширення
Підсумуємо: ми починаємо з референсного стану, потім еволюціонуємо його впродовж різних проміжків часу, щоб згенерувати унітарний підпростір Крилова. Ми проєктуємо наш гамільтоніан на цей підпростір. Також оцінюємо перекривання векторів підпростору. Нарешті, класично розв'язуємо нижньовимірну узагальнену задачу на власні значення.
Порівняємо, що визначає обчислювальні витрати при використанні методу Крилова класично і квантово. Класичний та квантовий підходи не мають досконалих аналогів для всіх кроків. Ця таблиця містить деякі оцінки масштабування різних кроків для порівняння.
Нагадаємо, що гамільтоніани загалом містять члени, які не можна виміряти одночасно (оскільки вони не комутують між собою). Ми сортуємо члени гамільтоніана на групи комутуючих операторів Паулі, які можна вимірювати одночасно, і нам може знадобитися багато таких груп, щоб врахувати всі члени, що не комутують. Для побудови на квантовому комп'ютері потрібні окремі вимірювання для кожної групи комутуючих рядків Паулі в гамільтоніані, і для кожної з них потрібно багато знімків. Це треба зробити для різних матричних елементів, що відповідає комбінаціям різних факторів часової еволюції. Іноді є способи скоротити це, але в грубому наближенні час, необхідний для цього, масштабується як . Елементи потрібно оцінити, що масштабується як . Нарешті, розв'язання узагальненої задачі на власні значення у проєкційному просторі класично займає .
Бачимо, що квантова діагоналізація Крилова може бути корисною у випадках, коли кількість комутуючих груп Паулі в гамільтоніані відносно мала. Ці залежності масштабування вказують на деякі застосування, де метод Крилова може бути корисним, і на інші, де, мабуть, ні. Деякі гамільтоніани мають велику складність при відображенні на кубіти — вони містять багато некомутуючих рядків Паулі, які важко розбити на невелику кількість комутуючих груп. Це часто справедливо для задач квантової хімії, наприклад. Така складність породжує дві основні проблеми для квантових комп'ютерів найближчого часу:
- Оцінка кожного елемента стає обчислювально дорогою через велику кількість членів.
- Необхідні схеми Троттера стають надміру глибокими.
Обидва зазначені пункти будуть менш проблематичними, коли квантові комп'ютери досягнуть відмовостійкості, але їх треба враховувати в найближчій перспективі. Навіть системи з «простішими» відображеннями, ніж у квантовій хімії, можуть стикатися з тими самими перешкодами, якщо гамільтоніани містять занадто багато некомутуючих членів. Метод Крилова найбільш корисний там, де гамільтоніан можна розбити на відносно невелику кількість комутуючих груп Паулі, і де легко реалізувати у схемах Троттера. Обидві ці умови виконуються, наприклад, для багатьох ґраткових моделей, що становлять інтерес у фізиці. KQD особливо корисний, якщо про основний стан відомо дуже мало. Це випливає з притаманних йому гарантій збіжності та застосовності в сценаріях, де альтернативні методи неприйнятні через недостатнє знання основного стану.
Хоча KQD є потужним інструментом, найбільш витратні аспекти протоколу — зокрема оцінка кожного елемента проєктованого гамільтоніана та перекривання станів Крилова — відкривають можливості для вдосконалення. Альтернативний підхід передбачає поєднання методів Крилова з методами на основі вибірки, яким присвячено наступний урок.
6. Додатки
Додаток I: Підпростір Крилова з еволюцій у реальному часі
Унітарний простір Крилова визначається як
для деякого кроку часу , який ми визначимо пізніше. Тимчасово припустимо, що парне: тоді визначимо . Зауважимо, що при проєктуванні гамільтоніана на наведений вище простір Крилова, його неможливо відрізнити від простору Крилова
тобто того, де всі часові еволюції зсунуті назад на кроків. Причина нерозрізнимості полягає в тому, що матричні елементи
інваріантні відносно загального зсуву часу еволюції, оскільки оператори часової еволюції комутують з гамільтоніаном. Для непарного можна скористатися аналізом для .
Ми хочемо показати, що десь у цьому просторі Крилова гарантовано є низькоенергетичний стан. Зробимо це за допомогою наступного результату, що виводиться з теореми 3.1 у [3]:
Твердження 1: існує функція така, що для енергій у спектральному діапазоні гамільтоніана (тобто між енергією основного стану та максимальною енергією)...
- для всіх значень , що відстоять від на , тобто функція експоненційно спадає
- є лінійною комбінацією для
Доведення наводиться нижче, але його можна сміливо пропустити, якщо немає потреби розуміти повний строгий аргумент. Зосередьмося на наслідках наведеного твердження. З властивості 3 видно, що наведений вище зсунутий простір Крилова містить стан . Це і є наш низькоенергетичний стан. Щоб зрозуміти чому, запишемо у власному базисі енергій:
де — -й власний стан енергії, а — його амплітуда в початковому стані . У цих позначеннях задається як
з урахуванням того, що можна замінити на , коли він діє на власний стан . Похибка енергії цього стану тому дорівнює
Щоб перетворити це на більш зрозумілу верхню оцінку, спочатку розіб'ємо суму в чисельнику на члени з і члени з :
Перший член можна обмежити зверху через :
де перший крок випливає з того, що для кожного у сумі, а другий — з того, що сума в чисельнику є підмножиною суми в знаменнику. Для другого члена спочатку обмежимо знаменник знизу через , оскільки : зібравши все разом, отримаємо
Щоб спростити те, що залишилось, зауважимо, що для всіх цих , за визначенням , виконується . Додатково обмеживши зверху та зверху, отримаємо
Це справедливо для будь-якого , тому якщо покласти рівним бажаній похибці, то наведена верхня оцінка похибки експоненційно збігається до неї зі збільшенням розмірності Крилова . Зауважимо також, що якщо , то член у наведеній оцінці взагалі зникає.
Щоб завершити аргумент, зазначимо, що наведене вище — це лише похибка енергії конкретного стану , а не похибка стану з найменшою енергією у просторі Крилова. Однак за варіаційним принципом (Релея–Рітца) похибка енергії стану з найменшою енергією у просторі Крилова обмежена зверху похибкою енергії будь-якого стану в цьому просторі, тому наведена оцінка є також верхньою оцінкою для похибки стану з найменшою енергією, тобто результату алгоритму квантової діагоналізації Крилова.
Аналогічний аналіз можна провести з урахуванням шуму та процедури порогового відсіювання, що обговорюється в ноутбуці. Дивись [2] та [4] для цього аналізу.
Додаток II: доведення Твердження 1
Наведене нижче здебільшого виведено з [3], Теорема 3.1: нехай і нехай — простір залишкових поліномів (поліномів, значення яких у точці 0 дорівнює 1) степеня не більше ніж . Розв'язок задачі
є
а відповідне мінімальне значення дорівнює
Нам потрібно перетворити це у функцію, яку зручно виражати через комплексні експоненти, адже саме вони є еволюціями в реальному часі, що породжують квантовий простір Крилова. Для цього зручно ввести таке перетворення енергій у спектральному діапазоні гамільтоніана до чисел у діапазоні : визначимо
де — часовий крок такий, що . Зауваж, що , а зростає зі збільшенням відстані від .
Тепер, використовуючи поліном з параметрами a, b, d, встановленими як , та d = int(r/2), визначимо функцію:
де — енергія основного стану. Підставляючи , можна переконатися, що є тригонометричним поліномом степеня , тобто лінійною комбінацією для . Більше того, з визначення вище випливає, що , і для будь-якого у спектральному діапазоні такого, що , маємо
Посилання:
[1] https://arxiv.org/abs/2407.14431
[2] https://arxiv.org/abs/1811.09025
[3] https://people.math.ethz.ch/~mhg/pub/biksm.pdf
[4] https://academic.oup.com/book/36426
[5] https://en.wikipedia.org/wiki/Krylov_subspace
[6] Krylov Subspace Methods: Principles and Analysis, Jörg Liesen, Zdenek Strakos https://academic.oup.com/book/36426
[7] Iterative Methods for Sparse Linear Systems" by Yousef Saad
[8] "MINRES-QLP: A Krylov Subspace Method for Indefinite or Singular Symmetric Systems" by Sou-Cheng Choi, Christopher Paige, and Michael Saunders (https://epubs.siam.org/doi/10.1137/100787921)
[9] Ethan N. Epperly, Lin Lin, and Yuji Nakatsukasa. "A theory of quantum subspace diagonalization". SIAM Journal on Matrix Analysis and Applications 43, 1263–1290 (2022).